版本 72f3d3728fb883cc4619470fcdfe4eb84dd23669
Changes from 72f3d3728fb883cc4619470fcdfe4eb84dd23669 to current
---
title: ARM-Linux
categories: embedded, arm, cortex-a, cortex-a8, linux, arm-linux,lmbench
categories: embedded, arm, cortex-a, cortex-a8, linux, arm-linux,lmbench ,ftrace , kernelshark
...
協作者
------
* 2015 年春季
- 洪文麟, 蔣亞翰, 邱酩仁, 張家榮, 顧又榮
- [洪文麟](https://github.com/hkuro), [蔣亞翰](https://github.com/r930709), [邱酩仁](https://github.com/vodkaice), [張家榮](https://github.com/JaredCJR), [顧又榮](https://github.com/iGaryGu)
共筆
----
* 2015 年春季: `hackpad <https://embedded2015.hackpad.com/Team6--D3q9lvQUPDH>`_
* 2015 年春季: [hackpad ](https://embedded2015.hackpad.com/Team6--D3q9lvQUPDH)
硬體及測試平台
------------------------------------------------
- 電腦端:
- Intel i5/i7
- Ubuntu 14.10 64 bit
- Lubuntu 14.10 64 bit
- 測試硬體:
- BeagleBone Black:
- ARM Cortex A8
- AM3358
- 測試平台:
- arm-Linux
- `Angstrom<https://github.com/beagleboard/kernel/tree/3.8>`_
- [Angstrom](https://github.com/beagleboard/kernel/tree/3.8)
- Kernel version:3.8
編譯arm-Linux(Angstrom)給BeagleBone Black
------------------------------------------------
- Environment
.. code-block:: txt
$sudo apt-get install zlib1g-dev libsdl1.2-dev build-essential ddd cpio libncurses5-dev u-boot-tools
$sudo apt-get install lib32gcc1 ( 64-bit required)
$sudo apt-get install gcc-arm-linux-gnueabi
$sudo apt-get install lzop
```
$ sudo apt-get install zlib1g-dev libsdl1.2-dev build-essential ddd cpio libncurses5-dev u-boot-tools
$ sudo apt-get install lib32gcc1 ( 64-bit required)
$ sudo apt-get install gcc-arm-linux-gnueabi
$ sudo apt-get install lzop
```
- 切割SD card
- `mkcard.sh<https://github.com/nmenon/uomapfs/blob/master/scripts/mkcard.sh>`_
- $sh –x `mkcard.sh<https://github.com/nmenon/uomapfs/blob/master/scripts/mkcard.sh>`_ /dev/sdX;X為主機內看到的sd 卡掛載點 ex.sdb
- [mkcard.sh](https://github.com/nmenon/uomapfs/blob/master/scripts/mkcard.sh)
- $sh –x [mkcard.sh](https://github.com/nmenon/uomapfs/blob/master/scripts/mkcard.sh) /dev/sdX;X為主機內看到的sd 卡掛載點 ex.sdb
- Bootloader
.. code-block:: txt
抓source檔
```
$ git clone git://git.denx.de/u-boot.git
$ cd u-boot/
$ git checkout v2015.01 -b tmp
```
下載一個屬於am335x的環境patch檔
```
$ wget -c https://raw.githubusercontent.com/eewiki/u-boot-patches/master/v2015.01/0001-am335x_evm-uEnv.txt-bootz-n-fixes.patch
編譯
make ARCH=arm CROSS_COMPILE=arm-linux-gnueabi- distclean
make ARCH=arm CROSS_COMPILE=arm-linux-gnueabi- am335x_evm_defconfig
make ARCH=arm CROSS_COMPILE=arm-linux-gnueabi- -j4
```
- Kernel
.. code-block:: txt
抓source檔
```
$ git clone git://github.com/beagleboard/kernel.git
$ cd kernel
$ git checkout 3.8
$ ./patch.sh ##This step may take 10 minutes or longer
```
編譯
```
$ cp configs/beaglebone kernel/arch/arm/configs/beaglebone_defconfig
$ wget http://arago-project.org/git/projects/?p=am33x-cm3.git\;a=blob_plain\;f=bin/am335x-pm-firmware.bin\;hb=HEAD -O kernel/firmware/am335x-pm-firmware.bin
$ cd kernel
$ make ARCH=arm CROSS_COMPILE=arm-linux-gnueabi- beaglebone_defconfig
$ make ARCH=arm CROSS_COMPILE=arm-linux-gnueabi- uImage dtbs
$ make ARCH=arm CROSS_COMPILE=arm-linux-gnueabi- uImage-dtb.am335x-boneblack
$ make ARCH=arm CROSS_COMPILE=arm-linux-gnueabi- modules -j4
```
- uEnv.txt
.. code-block:: txt
```
mmcroot=/dev/mmcblk0p2 rw
mmcrootfstype=ext4 rootwait
console=ttyO0,115200n8
kernel_file=zImage
fdtfile=am335x-boneblack.dtb
loadaddr=0x80008000
fdtaddr=0x88000000
initrd_high=0xffffffff
fdt_high=0xffffffff
ipaddr=192.168.0.25
serverip=192.168.0.20
rootpath=/home/andy/beaglebone/nfs
loadfdt=fatload mmc 0:1 ${fdtaddr} ${fdtfile}
loadkernel=fatload mmc 0:1 ${loadaddr} ${kernel_file}
#boot from nfs
#netargs=setenv bootargs console=${console} ${optargs} root=/dev/nfs nfsroot=${serverip}:${rootpath},${nfsopts} rw ip=${ipaddr}:${serverip}::255.255.255.0:
#netboot=echo Booting from network ...;run netargs; bootz ${loadaddr} - ${fdtaddr}
#uenvcmd=run loadkernel;run loadfdt;run netboot;
#boot from sdcard
loadfiles=run loadkernel; run loadfdt
uenvcmd=mmc rescan;run loadkernel;run loadfdt; run fdtboot
fdtboot=run mmc_args; bootz ${loadaddr} - ${fdtaddr}
mmc_args=setenv bootargs console=${console} root=${mmcroot} rootfstype=${mmcrootfstype}
```
- Filesystem
.. code-block:: txt
到此網站抓取檔案系統 :�http://downloads.angstrom-distribution.org/demo/beaglebone/
選擇 : �Angstrom-systemd-image-eglibc-ipk-v2012.12-beaglebone-2013.09.12.rootfs.tar.xz
$tar –Jxvf Angstrom-systemd-image-eglibc-ipk-v2012.12-beaglebone-2013.09.12.rootfs.tar.xz
到此網站抓取檔案系統: http://downloads.angstrom-distribution.org/demo/beaglebone/
選擇 : Angstrom-systemd-image-eglibc-ipk-v2012.12-beaglebone-2013.09.12.rootfs.tar.xz
```
$ tar –Jxvf Angstrom-systemd-image-eglibc-ipk-v2012.12-beaglebone-2013.09.12.rootfs.tar.xz
```
- 將此filesystem放入rootfs磁區
- 將以下檔案放入到boot磁區
- uEnv.txt
- MLO
- u-boot.img
- zImage({kernel}/arch/arm/boot/zImage)
- am335x-boneblack.dtb({kernel}/arch/arm/boot/dts/am335x-boneblack.dtb)
Lmbench 3.0 測試方法分析
------------------------------------------------
- 簡介
- Lmbench 3 是一套可移植性高的benchmark,由許多小的benchmark module組成,具有不少測試功能
- Bandwidth benchmarks
- Cached file read
- Memory copy (bcopy)
- Memory read
- Memory write
- Pipe
- TCP
- Latency benchmarks
- Context switching.
- Networking: connection establishment, pipe, TCP, UDP, and RPC hot potato
- File system creates and deletes.
- Process creation.
- Signal handling
- System call overhead
- Memory read latency
- Miscellanious
- Processor clock rate calculation
- 簡易說明lmebnch測量latency方式:
- repetition
- (執行"repetition次"結果的加總,在除以"repetition次"),就當作"這次"測量的結果
- 一次的測試,latency = (執行時間/iterations)
- iterations為`mhz benchmark<http://www.bitmover.com/lmbench/mhz-usenix.pdf>`_測量,故不是定值,用以確保執行時間夠長,具有代表意義。
- iterations為[mhz benchmark](http://www.bitmover.com/lmbench/mhz-usenix.pdf)測量,故不是定值,用以確保執行時間夠長,具有代表意義。
- 執行時間不同當然是因為硬體不同所造成,然而影響最多的就是CPU架構,為了量測出準確的執行時間,必須將不確定因素降到最低,且時間與時脈(倒數關係)息息相關。
- GCD法(最大公因數),必須挑選互相有相依性的指令,因為pipeline的關係,導致cycles變少,且必須防止compiler優化,導致指令不按照預期執行:
.. code-block:: txt
如果一個CPU時脈為120Mhz,且執行以下兩個指令
1. SHR (2 cycles)
2. SHR;ADD (3 cycles)
如果執行時間為:
1. SHR 11.1ns (2 cycles)
2. SHR;ADD 16.6ns (3 cycles)
可以看出average CPI = 1.5
GCD 為 5.55ns,平均一個指令執行1.5*5.55ns , 其倒數(1/1.5*5.55)即為120Mhz,與原先假設相同
compiler的優化例子:
a+=a; // ADD optimized to a=0
a&=a; // AND optimized away completely
a^=a; // XOR optimized to a=0
a+=b; // ADD optimized to a+=b+b+b+…
因此mhz挑選了9組指令:
1. p=*p;
2. a^=a+a;
3. a^=a+a+a;
4. a>>=b;
5. a>>=a+a;
6. a^=a<<b;
7. a^=a+b;
8. a+=(a+b)&07;
9. a++;a^=1;a<<=1;
實際上在source code發現,iterations的值是經由一個迴圈去不斷測試值是否大於需求(根據`mhz benchmark作者自己說<http://www.bitmover.com/lmbench/mhz-usenix.pdf>`_,是150ms)
.. code-block:: c
實際上在source code發現,iterations的值是經由一個迴圈去不斷測試值是否大於需求(根據[mhz benchmark作者自己說](http://www.bitmover.com/lmbench/mhz-usenix.pdf),是150ms)
```c
#define BENCH_INNER(loop_body, enough) { \
static iter_t __iterations = 1; \
int __enough = get_enough(enough); \
iter_t __n; \
double __result = 0.; \
\
while(__result < 0.95 * __enough) { \
start(0); \
for (__n = __iterations; __n > 0; __n--) { \
loop_body; \
} \
__result = stop(0,0); \
if (__result < 0.99 * __enough \
|| __result > 1.2 * __enough) { \
if (__result > 150.) { \
double tmp = __iterations / __result; \
tmp *= 1.1 * __enough; \
__iterations = (iter_t)(tmp + 1); \
} else { \
if (__iterations > (iter_t)1<<27) { \
__result = 0.; \
break; \
} \
__iterations <<= 3; \
} \
} \
} /* while */ \
save_n((uint64)__iterations); settime((uint64)__result); \
}
```
`參考資料<http://www.bitmover.com/lmbench/mhz-usenix.pdf>`_
[參考資料](http://www.bitmover.com/lmbench/mhz-usenix.pdf)
Context Switch Latency on BeagleBone Black(Linux)
-----------------------------------------------------
- 取得lmbench並編譯給BBB(arm-linux)
- 由於lmbench 3已經很久沒有更新,lmbench-next為基於Linux的優化開源專案,並不保證能夠正常運作於non-Linux system
.. code-block:: txt
```
git clone https://github.com/el8/lmbench-next.git
cd lmbench-next
make ARCH=arm CROSS_COMPILE=arm-linux-gnueabi-
```
Context Switch Latency 測試理論
=================================================
**Abstract Machine Model:**
.. image:: /embedded/arm_linux/Abstract_Machine_Model_1.png

- 方程式(1):
- TA,M: <程式A>在<機器M>上執行的總時間
- Ci,A(數量): <程式A><指令i>的執行次數
- Pi,M(時間): <指令i>在<機器M>上的執行時間
.. image:: /embedded/arm_linux/Abstract_Machine_Model_2.png
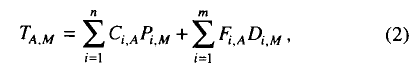
- 方程式(2):(多了cahce/TLB miss)
- Fi,A (faults):為記憶體階層的第i層的miss次數
- Di,M (delay):每次miss所付出的懲罰
**論文實驗方法:**
- 測試參數:
- Stride: s
- Array size : one-dimensional array of N k-bytes
- Cache/TLB size: C k-bytes
- Cache Line size:b words
- Cache Associativity: a
- 基本假設:
- 只有L1 cache
- Instruction Cache與Data Cache為獨立的
- Data Cache可用Virtual Address(以後皆稱VA)定址:意思就是記憶體為"連續的區域"
- 子集合的基本單位(by sequence number): 1, s + 1, 2s + 1, ..., N - s + 1.
- Cache更新的機制為write-through
- Tno-miss可能包含處理器被強制等待write buffer back up的時間
**論文實驗分類與討論:**
.. image:: /embedded/arm_linux/tlb_experiment_table.png
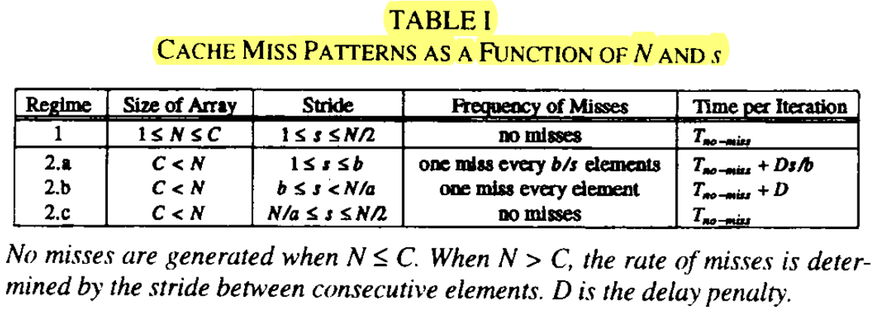
- REGIME 1:
- N <= C
- C為cache的容量
- N為array size
- 只要array被載入,就不再有cache miss出現,也就是永遠只有第一次載入時,會有cache miss
- 每次遞迴的執行時間(Tno-miss)包含讀取一個Array的子集合的基本單位(stride),計算,以及將結果存回Cache
- REGIME 2.a :
- array比cahce size大,所以一次沒有辦法全部讀進cahce
- stride比line size小,所以取一次array不一定會超過cache的大小,會有s/b次miss
- b/s個連續存取到同一個 cache line.
- 第一次載入array,總是Cache miss,REGIME 2 三種討論皆是如此,不再重述。
- 因此執行時間為Tno-miss + D*s/b ;D為delay penalty(代表從主記憶體讀取資料然後恢復執行的時間)
- 現代的cache不以byte為單位了,以cache line為一次抓取資料的單位,故2.a方法已經不再討論,也無法驗證,但是可以驗證line size(如下驗證)
**驗證line size造成的miss的影響:**
- test_line.c
.. code-block:: c
```c
#include<stdio.h>
#include<sys/time.h>
#include<unistd.h>
#include<stdlib.h>
int arr[64 * 1024 * 80] = { 2 };//just for big enough
int test_line(int step)
{
struct timeval start;
struct timeval end;
long unsigned int i = 0;
gettimeofday(&start, NULL);
for (; i < (int)(sizeof(arr)/sizeof(int)); i += step)
{
arr[i] *= arr[i];
}
gettimeofday(&end, NULL);
return ( 1000000*(end.tv_sec - start.tv_sec)+ (end.tv_usec - start.tv_usec) ) ;
int test_line(int step) {
struct timeval start;
struct timeval end;
long unsigned int i = 0;
gettimeofday(&start, NULL);
for (; i < (int)(sizeof(arr)/sizeof(int)); i += step) {
arr[i] *= arr[i];
}
gettimeofday(&end, NULL);
return ( 1000000*(end.tv_sec - start.tv_sec)+ (end.tv_usec - start.tv_usec) ) ;
}
int main(int argc, char *argv[])
{
int test_step = atoi(argv[1]);
printf("%d %d\n", test_step, test_line(test_step));
return 0;
int test_step = atoi(argv[1]);
printf("%d %d\n", test_step, test_line(test_step));
return 0;
}
```
- shell script
.. code-block:: txt
```
#!/bin/bash
K="1 4 6 8 10 12 14 16 32 64 128 256"
#set -x
for size in $K
do
./test_line $size
done
echo "" 1>&2
```
.. image:: /embedded/arm_linux/line_size_compare.png
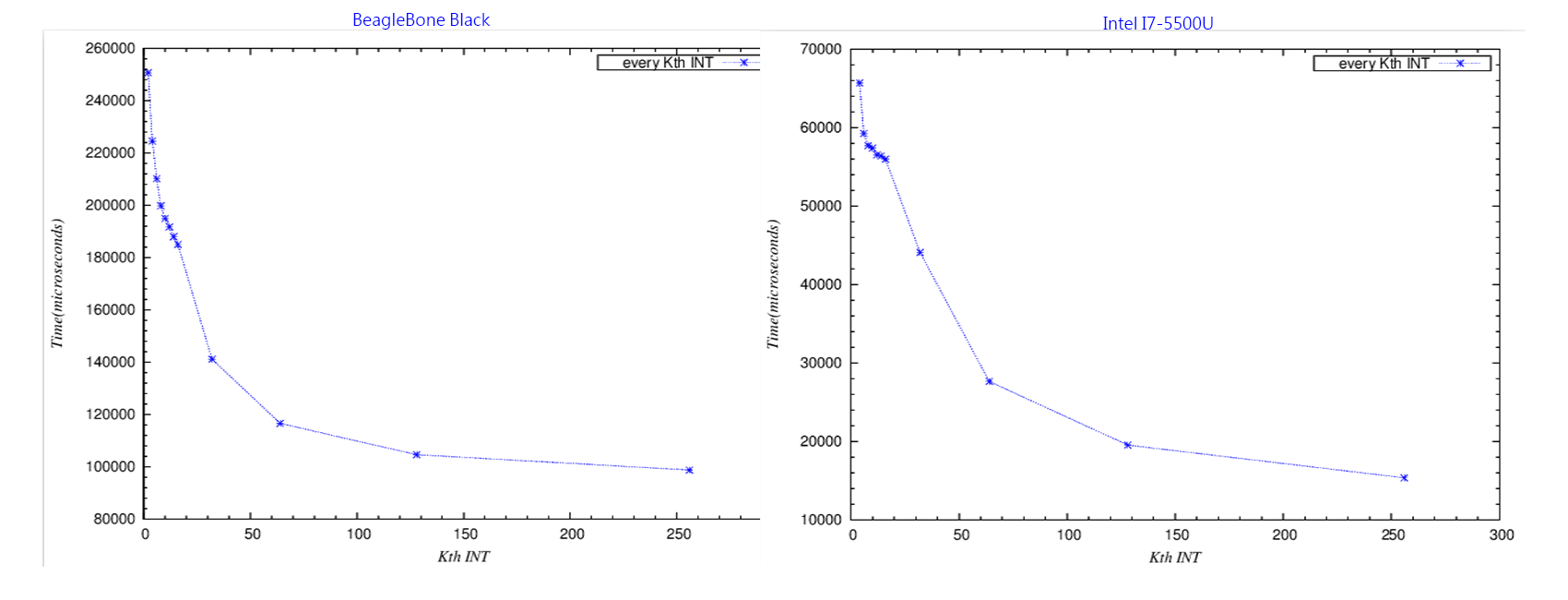
- 會同時放上BBB和i7-5500U的結果是因為,cache line miss的overhead固然不小,但由於BBB的CPU運算較慢,較不明顯,所以放上較快的i7-5500U做為比較,且兩者的L1 cache line size均為64bytes,另外,Y軸的時間差異不用太在意,重點是斜率。
- 原因:現代的cache一次是抓取一個line size的資料,在這裡就是64bytes,所以今天array一次就是讀64bytes進來,有以下幾個範例(注意:INT array一格的大小是4bytes,所以16個就是64bytes):
- k=1,array[0] => array[1] => array[2] => array[3] => ... => array[15]都算在同個line裡面,所以只有第一次array[0]會cache line miss,下一次就是array[16],依此類推
- k=4,array[0] => array[4] => array[8] => array[12] 都算在同個line裡面,所以只有第一次array[0]會cache line miss,下一次就是array[16],依此類推
- k=16,array[0] 算在同個line裡面,所以只有第一次array[0]會cache line miss,下一次就是array[16],依此類推
- k=32,array[0] 算在同個line裡面,所以只有第一次array[0]會cache line miss,下一次就是array[32],依此類推
- k=64,array[0] 算在同個line裡面,所以第一次array[0]會cache line miss,下一次就是array[64],依此類推
- k=128,array[0] 算在同個line裡面,所以第一次array[0]會cache line miss,下一次就是array[128],依此類推
消耗的時間為CPU運算時間+cache line miss的時間(沒有miss的讀取cache時間算在CPU運算的份上),可以發現在K<=16時,時間差異只有cache line miss,從圖中可發現,K <=16時,斜率較低,但消耗時間仍然有下降,是因為實質上CPU所運算的對象的確較少,然而到K=32時,CPU雖然運算比先前更少,但是可以看出line(cache) miss的影響比較大,因為同樣都是少了一半CPU運算的對象(k=8與k=16 vs k=16與k=32 vs k=32與k=64),但斜率下降更明顯,就是由於miss的次數少了一半。依此類推,K=64為K=16的miss次數的1/4,但是K=1到K=16的miss次數是一樣的,至於為什麼會這樣,見下圖說明,上面例子也可看出,K越大(K>=16時),下一次cache line miss的位置就越後面,但是array固定大小,所以相對就是cache line miss次數越少。
今天cache一次抓取line size大小的資料,所以64bytes以下的資料都會被抓進來,只是當K!=1且K<16時,會比K=1的情況下,運算較少次,但是miss次數是一樣的!
- 說明圖片:(int的大小為4 bytes時)
- 32byte為k=8的情況
- 64byte為k=16的情況
- 256byte為k=64的情況
- 碰到紅色代表會miss
.. image:: /embedded/arm_linux/line_size_illustrate2.png
- (Jared補充):感謝晶心科技的greentime指出:第一次cache miss,重新fetch到的資料開頭,不一定會如圖中對齊(cahce line開頭 v.s.array存取的位置),但實驗方法該如何修改,仍然在思考中

- 今天如果有一個夠大的array,一個line是64byte,那麼如果小於等於64bytes的K,會踩到N次<假設>的cache line miss,但是如果K=128bytes,由於會"跨過"某些cache line miss的"點"(因為沒有要用到那邊的資料),所以時間會大幅降低(因為cache miss的overhead很大,實際上是少了1/2的miss次數),若是K=256bytes,則為少了1/4的miss次數(相較於K<=64bytes)
- 在參考資料1中的example2,它也有說明。
- `參考資料1<http://igoro.com/archive/gallery-of-processor-cache-effects/>`_
- `參考資料2<https://www.scss.tcd.ie/Jeremy.Jones/CS3021/5%20caches.pdf>`_
- [參考資料1](http://igoro.com/archive/gallery-of-processor-cache-effects/)
- [參考資料2](https://www.scss.tcd.ie/Jeremy.Jones/CS3021/5%20caches.pdf)
- REGIME 2.b :
- Array size 比 cache容量大
- stride比line size大(意思是每次都會miss)
- stride比array size小
- 每次遞迴都會有cache miss,也就是說每個Array的子集合的基本單位(stride)對應到一個不同的cache line.
- 每次遞迴的執行時間為Tno-miss + D
- REGIME 2.c :
- array size比cache大
- stride介於array size 的1/2~1倍,所以第一次沒有讀進來的array,就再也讀不到了
- 記憶體位置映射到一個單位子集合的次數一定少於associativity,也就是這個情況下(2.c),除了第一次載入Array會有miss之外,就沒有miss了
- 如果array有N elements,只有N/s < a可以被實驗到,且他們個別都可以被放入一個單一的子集合(stride),也就是說N/a <= s.
- 每次遞迴的執行時間為Tno-miss
- 結論
- TLB的行為可視為與Cache一樣
- Cache/TLB size可藉由測試,當發現Latency time大幅上升時,藉由比較array size(實際上的情況下面會談到)可以知道,因為D(cache miss penality)通常大於Tno-miss
- Regime 2.a與2.b相較於2.c方法,可以用來解釋為什麼在`維基百科 wiki :CPU cache<http://en.wikipedia.org/wiki/CPU_cache>`_ 中,有一張圖及內容談到當cache associativity(也就是a)越大時,miss rate越小。
.. image:: /embedded/arm_linux/tlb_wiki_associativity.png
- 參考資料:
- `Measuring cache and TLB performance and their effect on benchmark runtimes<http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=467697&url=http%3A%2F%2Fieeexplore.ieee.org%2Fxpls%2Fabs_all.jsp%3Farnumber%3D467697>`_
- `整理這篇論文的過程<https://embedded2015.hackpad.com/Team6-ARM-Linux-lmbench-Rlcb2b5Bw6O#:h=IV.-EXPERIMENTAL-RESULTS-FOR-C>`_
- [Measuring cache and TLB performance and their effect on benchmark runtimes](http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=467697&url=http%3A%2F%2Fieeexplore.ieee.org%2Fxpls%2Fabs_all.jsp%3Farnumber%3D467697)
- [整理這篇論文的過程](https://embedded2015.hackpad.com/Team6-ARM-Linux-lmbench-Rlcb2b5Bw6O#:h=IV.-EXPERIMENTAL-RESULTS-FOR-C)
Context Switch Latency 理論與實際的結合
=================================================
- BBB的AM3358:
.. image:: /embedded/arm_linux/BBB_hardware_1.png

- L1 Data Cache與Instruction Cache互相獨立,均為32KB
- L2 Cache為256KB
.. image:: /embedded/arm_linux/BBB_hardware_2.png

**對應"Context Switch Latency 測試理論"**
.. image:: /embedded/arm_linux/partical_theory.png
.. image:: /embedded/arm_linux/partical_theory_2.png
Context Switch Latency 實驗過程
=================================================
- 因為Linux無法關閉L2 cache,且要將其他程式對cache的影響降到最低,使用sync及drop_caches
- sync && echo 3 > /proc/sys/vm/drop_caches
- 但還是有些許影響,因為清完cache後,Linux還是有其他程式使用cahce,無法避免
**shell script for 巨觀**
.. code-block:: txt
```
#!/bin/sh
WARMUPS=0
REPETITIONS=11
CTX="0 2 4 8 16 24 32"
N="2 4 6 8 10 12 16 24 32 48 64 72 96"
set -x
for size in $CTX
do
#flush cache
sync && echo 3 > /proc/sys/vm/drop_caches
bin/arm/lat_ctx \
-W $WARMUPS -N $REPETITIONS -s $size $N
done
echo "" 1>&2
```
**shell script for 微觀**
.. code-block:: txt
```
#!/bin/bash
WARMUPS=0
REPETITIONS=11
CTX="2 4 8 16 24 32"
N="2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35"
file_dest="./test_results/"
extension="k.txt"
mkdir -p $file_dest
set -x
for size in $CTX
do
for pnumber in $N
do
RUN="bin/arm/lat_ctx -W $WARMUPS -N $REPETITIONS -s $size $pnumber"
#flush cache
sync && echo 3 > /proc/sys/vm/drop_caches
file=$file_dest$size$extension
if test -s $file
then
$RUN >> $file 2>&1
else
$RUN > $file 2>&1
fi
done
done
echo "" 1>&2
```
Context Switch Latency 實驗結果 及 分析
=================================================
**折線圖可由斜率, 得到rate of time to Size(process number * process size),斜率突然暴增就是cache miss開始發生**
**長條圖可直接比較Y軸(時間),發現cache miss開始**
- L1 cache miss
- 採用Harvard architecture(data/instruction cache分開),分析起來相對於L2 cache容易
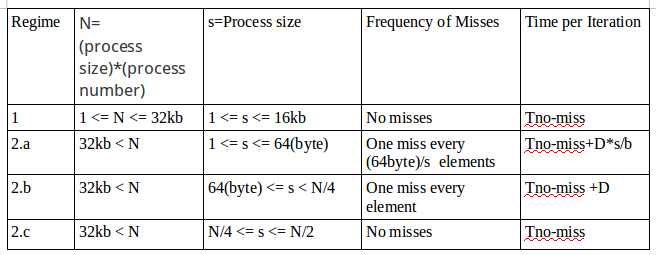
- 巨觀
.. image:: /embedded/arm_linux/2k_Macroscopic.png
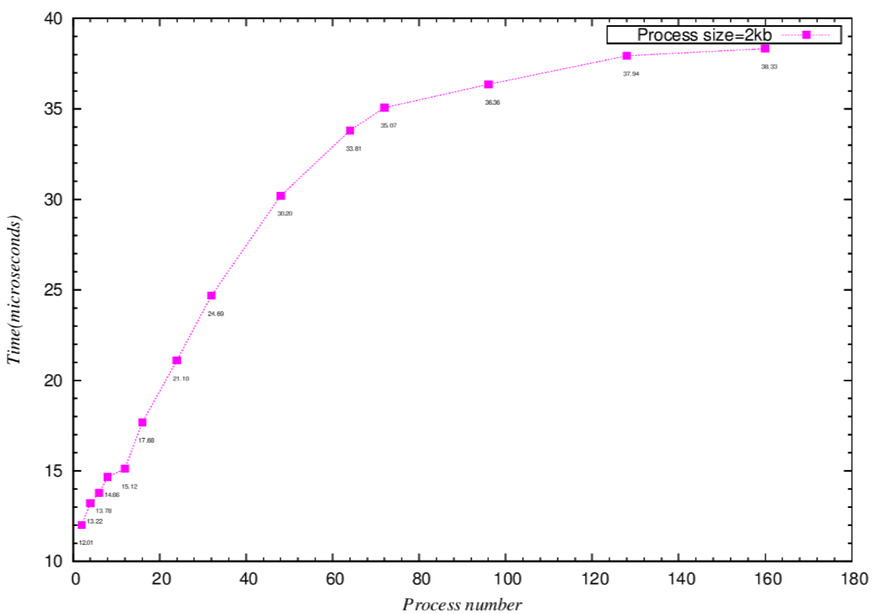
- 理論推算表格(僅取部分,作為代表,可依此類推)
.. image:: /embedded/arm_linux/partical_theory_2k_table.png
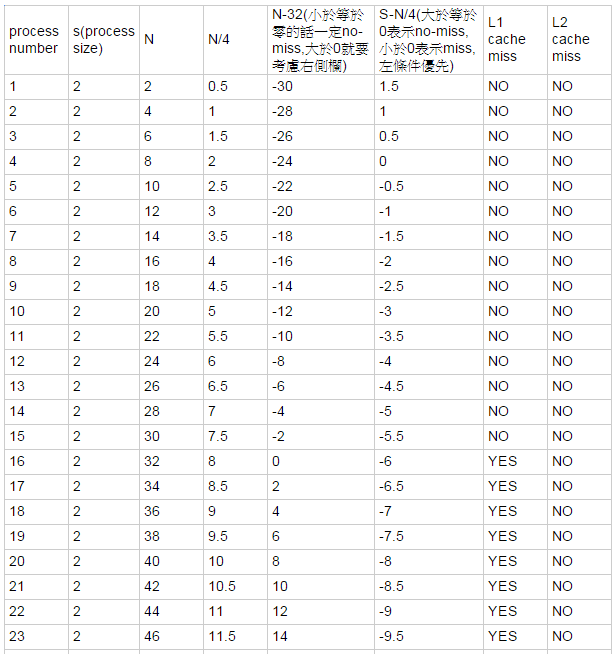
- 微觀折線圖
.. image:: /embedded/arm_linux/2k_Microcosmic.png
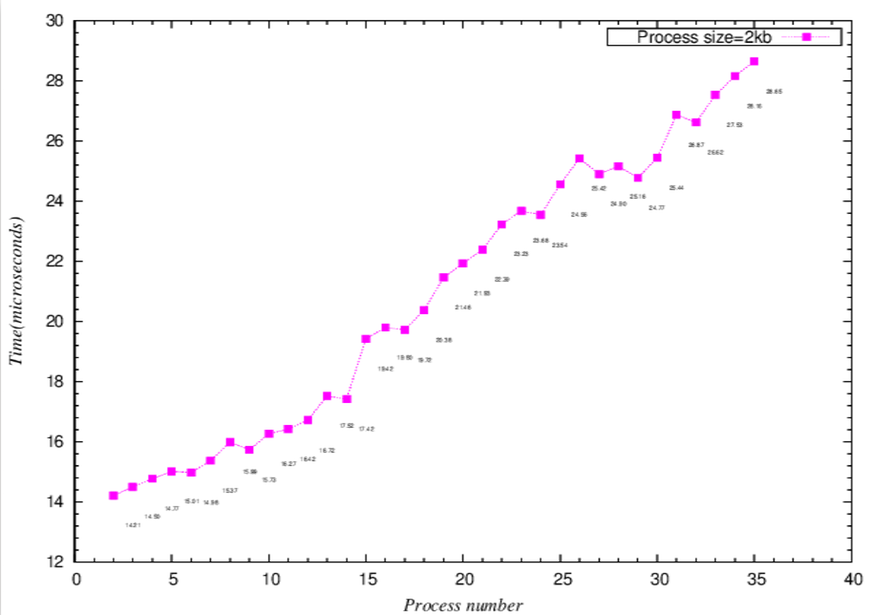
- 微觀長條圖-相較於折線圖,可以更明顯看到,當process number接近16(2k*16=32k,用接近是因為可能有其他程式也使用L1 cache)時,latency大幅上升
.. image:: /embedded/arm_linux/2k_Microcosmic_histogram.png
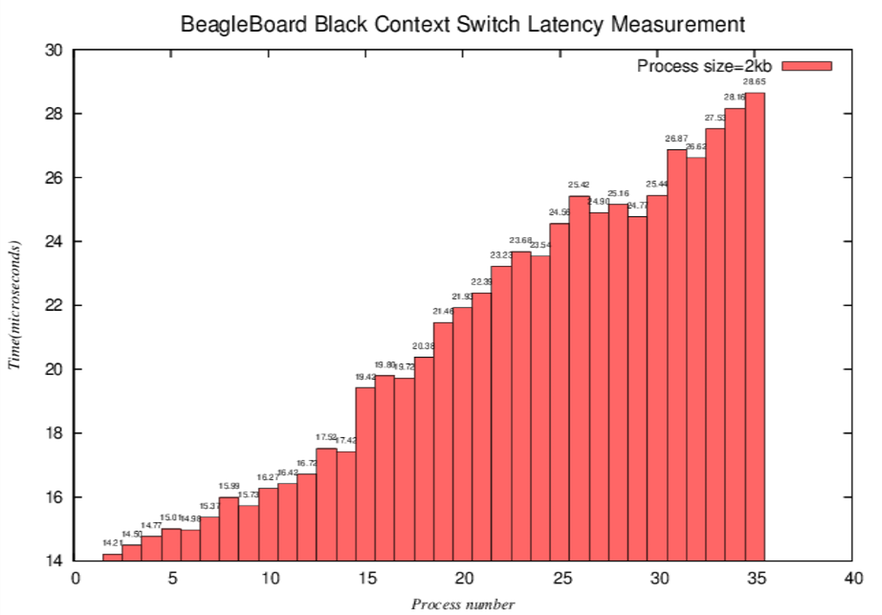
- L2 cache miss
- 由於L2 cahce採用von Neumann architecture(與L1 cache不同!),將data與instruction混合,不易分析,不過我們可以由實驗結果,看出一些端倪。
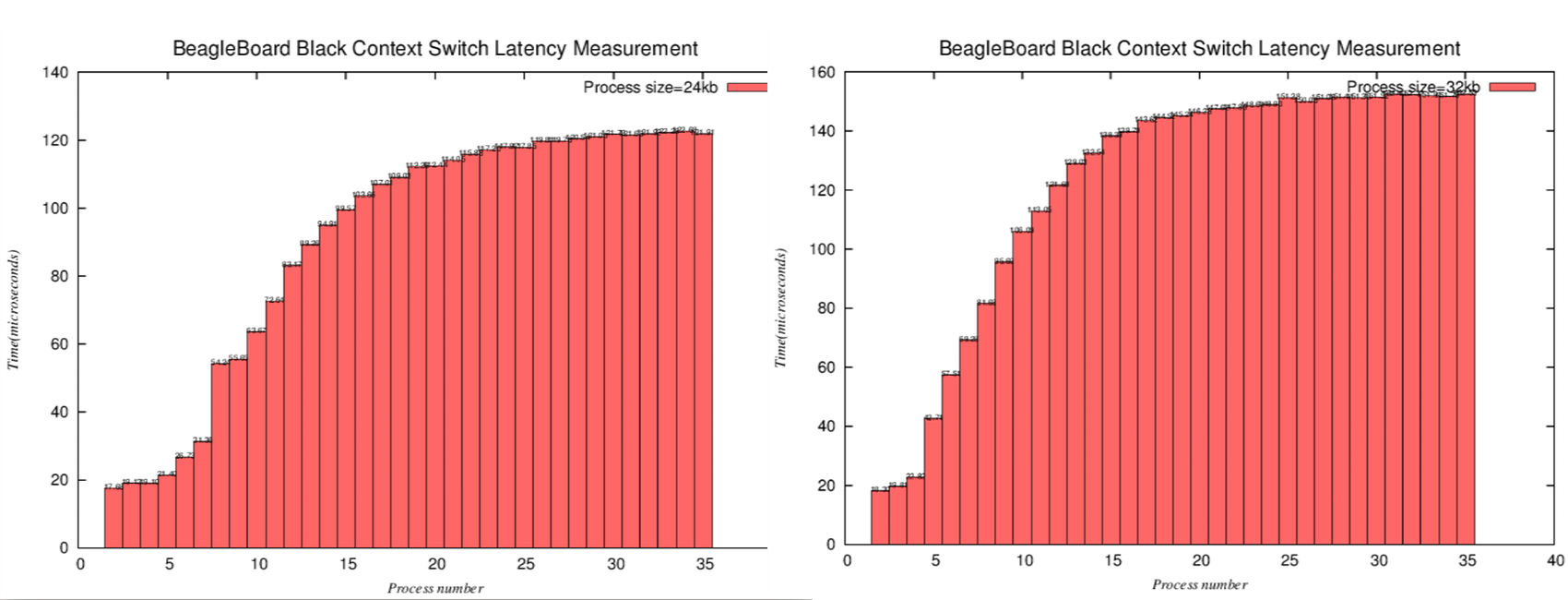
- process size=24k與32k之長條圖比較
.. image:: /embedded/arm_linux/24k_32k_histogram.png
- process size=24k與32k之折線圖比較
.. image:: /embedded/arm_linux/24k_32k.png
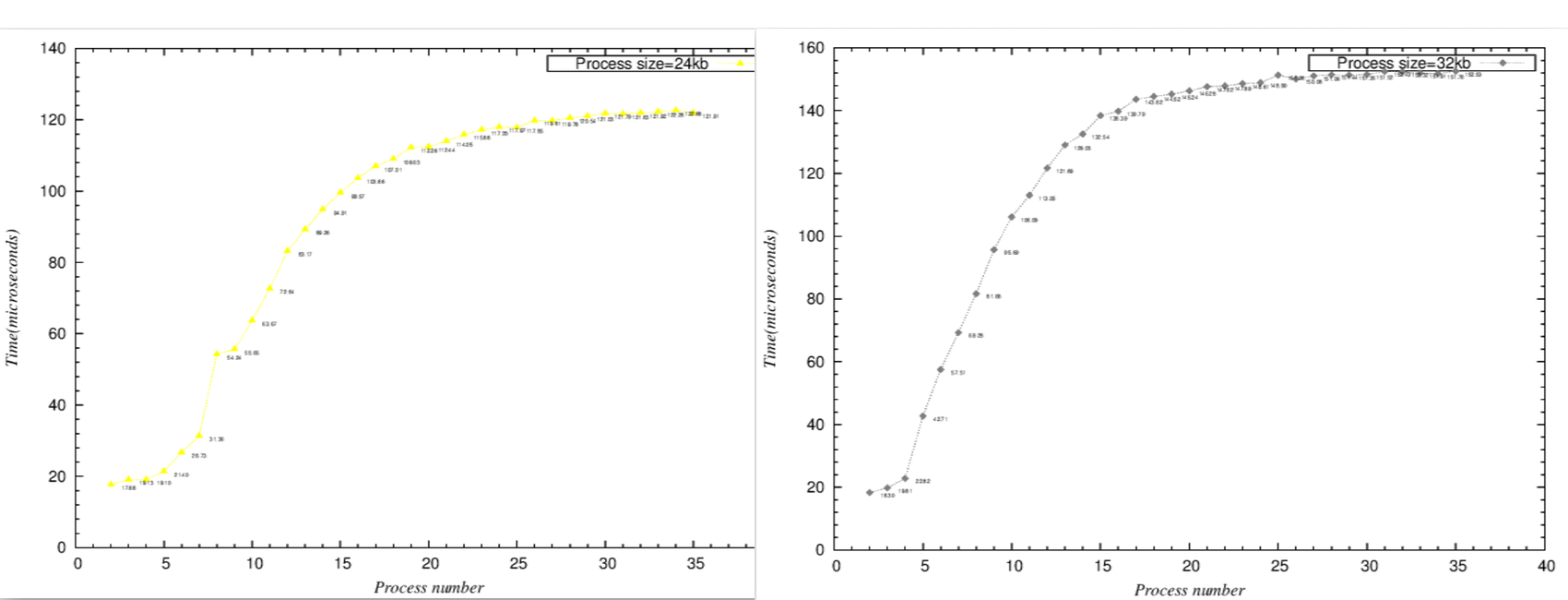
- 由以上2組比較圖,可以看出
- process size=24k時,process number=8,N=24*8=192,latency大幅上升,合理推測這時候L2 cache miss
- process size=32k時,process number=5,N=32*5=160,latency大幅上升,合理推測這時候L2 cache miss
- 這個範圍的變動除了L2 cache除了有其他程式使用外,相較於L1的單純,還要多考慮Instruction的影響。
- 巨觀整體趨勢圖
.. image:: /embedded/arm_linux/lat_ctx_all_Macroscopic.png
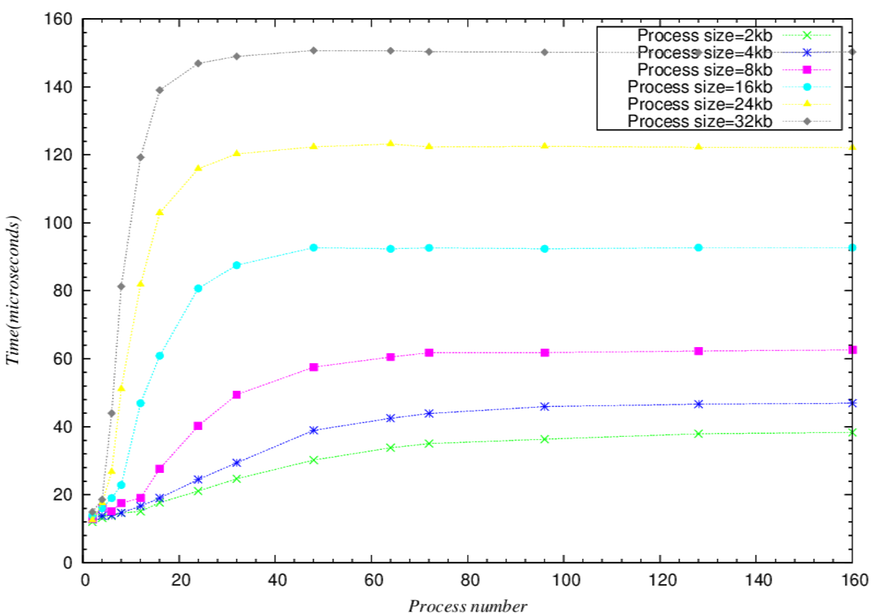
- 微觀整體趨勢圖
.. image:: /embedded/arm_linux/lat_ctx_all_Microcosmic.png
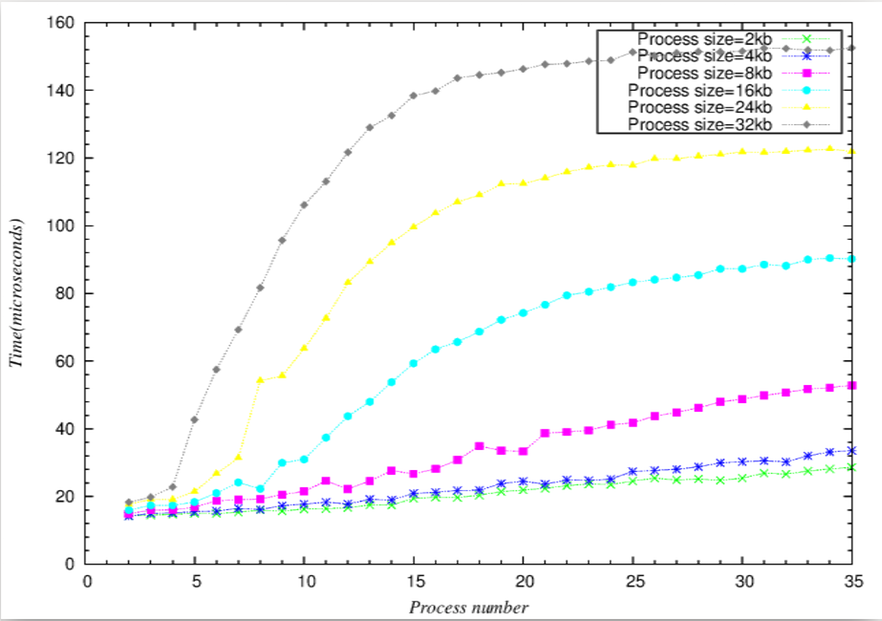
**Context Switch Latency 結論**
- 當(process size)*(process number)+(other program cache) > 32kb(L1 cache size)
- 比較=32kb與下一筆稍大於32kb的數據和下下一筆稍大於32kb的數據可以發現latency time是可以看出latency時間增幅會比較大的趨勢
- L1 cache miss penality影響甚巨。
- 當(process size)*(process number)+(other program cache)+(Instruction cache affect) > 256kb(L2 cache size)
- 相較於L1 cache的Harvard architecture,採用von Neumann architecture的L2確實比較難以測試出L2 cache的大小,但仍可看出,L2 cache miss的penality不容小覷,比L1 cache miss penality影響更多。
- 可以從整體趨勢發現,當N(process number * process size)大到某個程度後,latency的時間就趨近於固定的數字
- 可以看出如果process size越大,會越早到達"飽和"(就是比較快到他最終趨近的latency time)
- 注意事項:
- 這個測試必須注意BBB的散熱,吹冷氣+電風扇才不會造成異常結果。
System Call Latency on BeagleBone Black(Linux)
------------------------------------------------
- Lmbench3 lat_unix:
- lat_syscall - This is useful as a lower bound cost on anything that has to interact with the operating system.
- SYNOPSIS
```
lat_syscall [ -P <parallelism> ] [ -W <warmups> ] [ -N <repetitions> ] getppid | read | write | stat | fstat | open [ file ]
- DESCRIPTION
- getppid : measures how long it takes to do getppid( ). We chose getppid( ) because in all UNIX variants we are aware of, it requires a round-trip to/from kernel space and the actual work required inside the kernel is small and bounded.
- read : measures how long it takes to read one byte from /dev/zero. Note that some operating systems do not support /dev/zero.
- write: times how long it takes to write one byte to /dev/null. This is useful as a lower bound cost on anything that has to interact with the operating system.
- stat: measures how long it takes to stat( ) a file whose inode is already cached.
- fstat: measures how long it takes to fstat( ) an open file whose inode is already cached.
- open: measures how long it takes to open( ) and then close( ) a file.
```
- Intel core i5 lmbench3 lat_syscall
```
Simple syscall: 0.0516 microseconds
Simple open/close: 1.0371 microseconds
Simple read: 0.1096 microseconds
Simple write: 0.1173 microseconds
```
- Beaglebone black lmbench-next
```
Simple getppid: 0.5671 microseconds
Simple open/close: 11.5381 microseconds
Simple read: 0.9199 microseconds
Simple write: 0.9514 microseconds
```
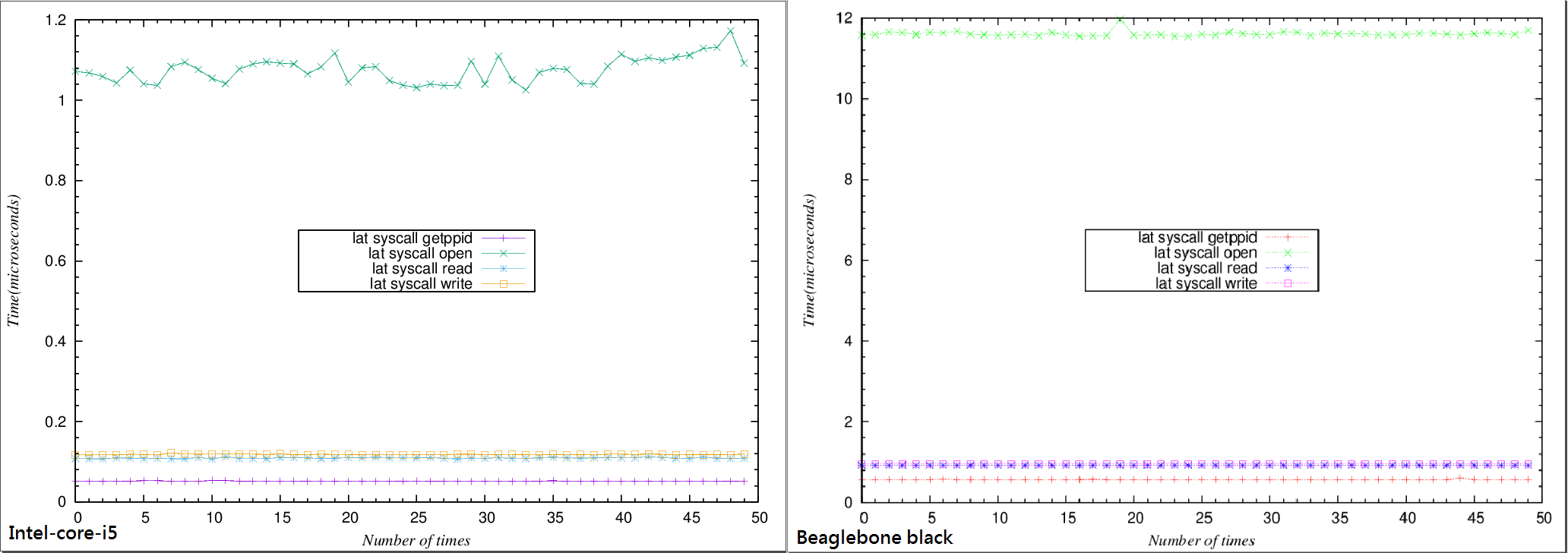
**結論**
- 可以從上圖看出syscall latency 不論在Intel-core-i5或者Beaglebone black上測出來都是一個穩定的值,藉此還能分別看出 getppid、open/close、read、write這幾個syscall 在其不同硬體上的latency會有不同。
Unix Latency on BeagleBone Black(Linux)
------------------------------------------------
- Lmbench3 lat_unix:
- lat_unix - 測量interprocess communication latency透過UNIX sockets
- "hot potato" benchmark
- benchmark不斷的在2個process間來回傳遞message
- process裡面沒有做任何事情
-測量出的數據( 第一欄為message size<byte>,第二欄為latency<microseconds> )
.. code-block:: txt
```
0 3.9333
1 45.2623
2 45.3115
3 45.5246
4 45.4098
5 45.5410
6 45.5702
7 45.5246
8 45.7870
10 45.5000
12 45.5289
16 45.7156
20 45.6694
24 45.7523
32 45.7870
48 46.1574
64 45.9752
96 45.9091
128 46.0965
196 46.2689
256 46.4434
384 46.6555
512 47.1887
```
.. image:: /embedded/arm_linux/lat_unix_LMA_RMI.png
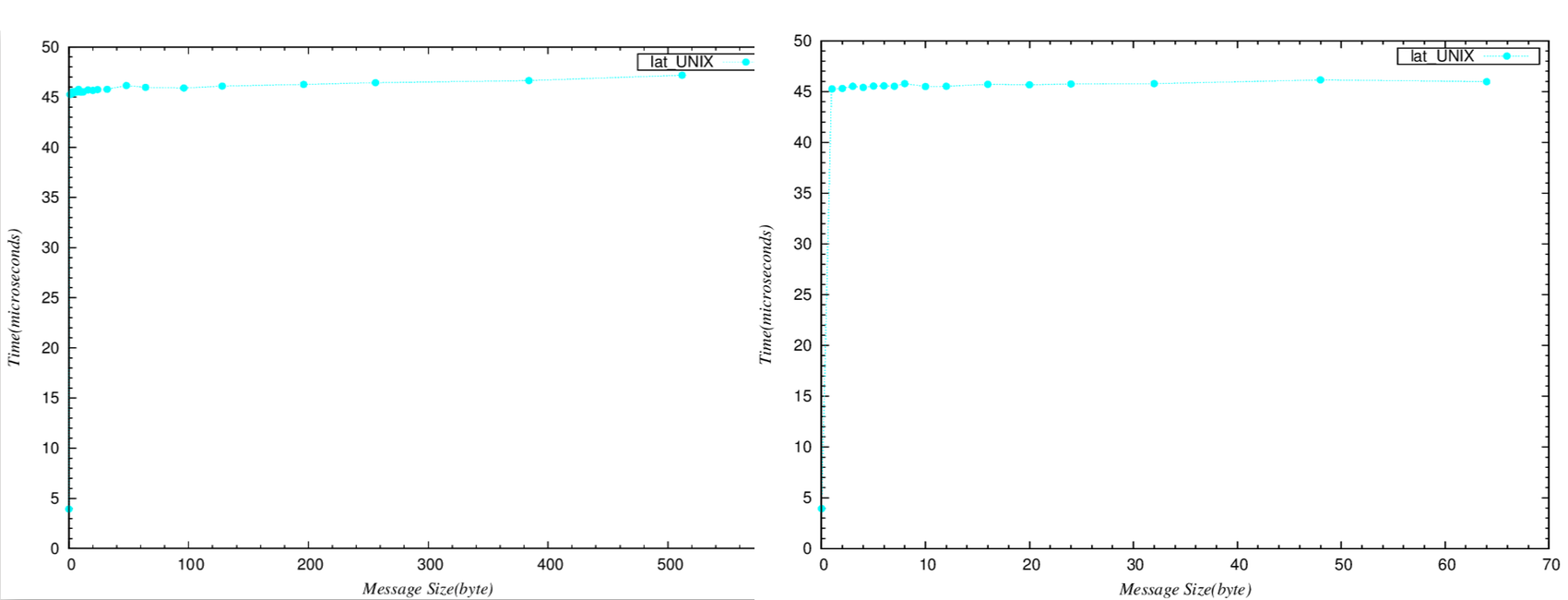
左邊為巨觀,右邊為微觀,可以看出斜率均趨近於0。
**結論**
- 不論傳遞的message多大(除了0之外),overhead都大約是46 microseconds
Memory Read Latency on BeagleBone Black(Linux)
------------------------------------------------
- 根據不同的記憶體大小與strides測量讀取記憶體的延遲時間
- 藉由man page 得知由memory read latency 所得到的數據可以判斷出測量平台的記憶體階層。
- 下圖比較memory size 1M、2M、4M、8M,以不同stride,在BeagleBone Black 上所測量到的數據(x軸為log2的基底)
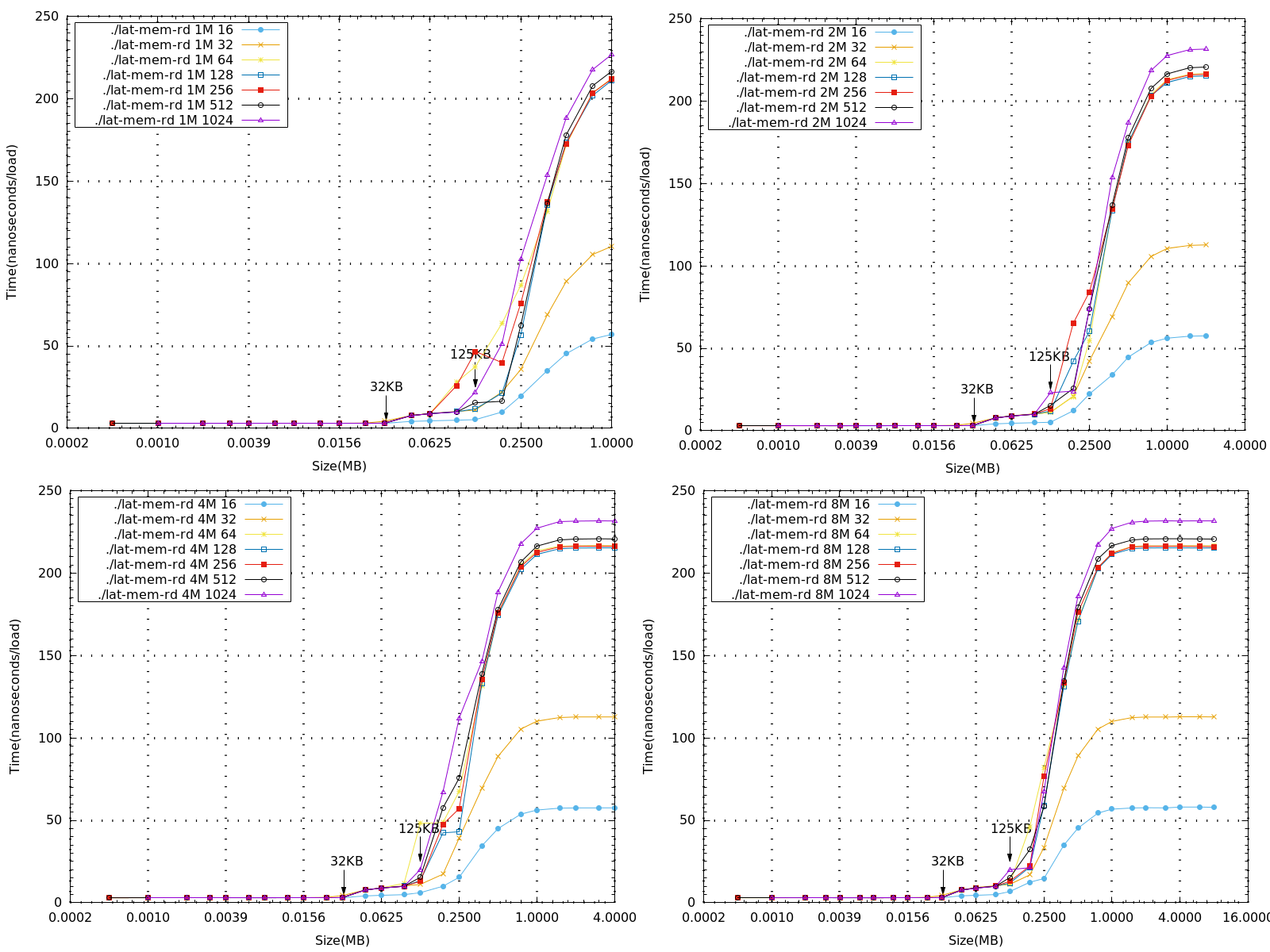
**分析**
#. 從上圖可以看到與理論相符的結果,在L1 cache=32 KB 的地方都會接著一個突起的值。也就是說,當要讀取的值超過L1 cache 的大小時,就必須往下一層的cache去存取資料,因此讀取的時間就會有一定幅度的增加。
#. 接著要看L2 cache,採用von Neumann architecture,將data與instruction混合,由上面的圖發現大約都是在size在125KB或187KB 時會接著一個突起的值。而BBB的L2 cache為256KB,因為還要再考慮其他程式與instruction的影響,且再與Context Switch Latency的實驗比較結果是相近的,所以與理論相符。
#. 當讀取的大小超過1M後,每筆資料都會趨近於一個定值,而不同的stride收斂的時間有些不同,stride=16的時間大約為stride=32的一半,從原始數據大看大約為57ns與110ns。當stride不超過line size的大小時,收斂的時間應是成線性比例的,這部分可以再做實驗收集數據看結果。
#. 再看到若當讀取的stride大小超過line size時,最後的收斂時間大約都相同,差不多在220ns左右。因為一次存取的大小就是一個line size,所以stride大於64的數據收斂時間都是差不多的。
**補充**
- 下圖為存取1M大小,在stride大小不超過line size的情況,可以發現收斂時間是呈現線性的。
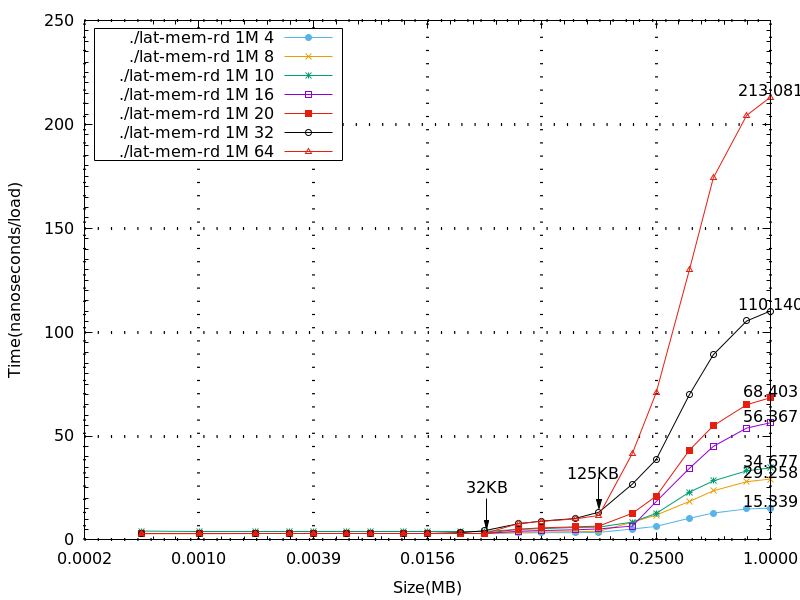
- 過程中發現stride=1、2 時數據測出來都是0,推測是因為memory在讀取的時候一次都是1 個word,所以stride=1、2是沒有意義的。
- 下列一系列圖為memory size=8M,不同stride,在beaglebone black 上所測量到的數據(x軸為log2的基底),單獨畫出來做比較
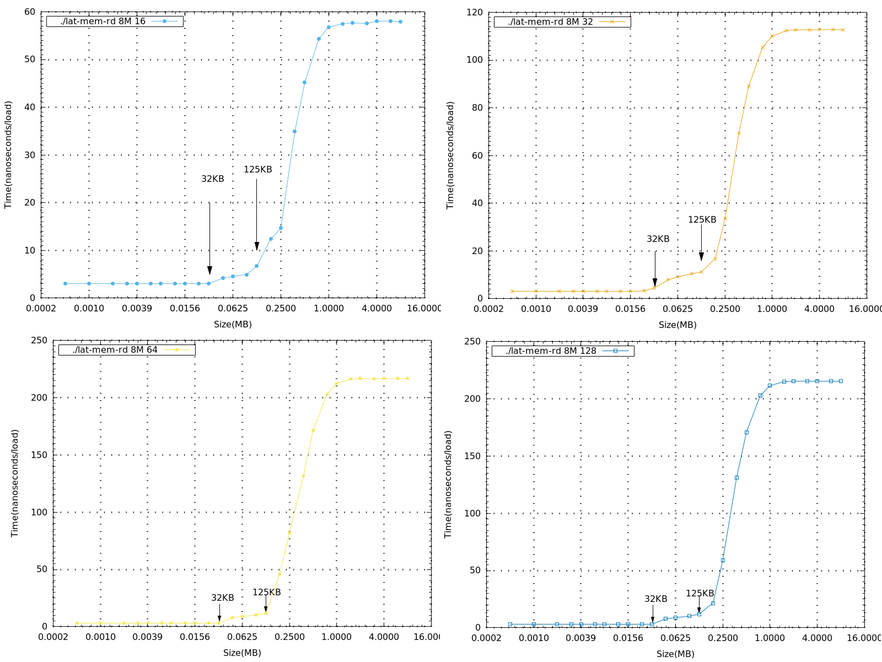
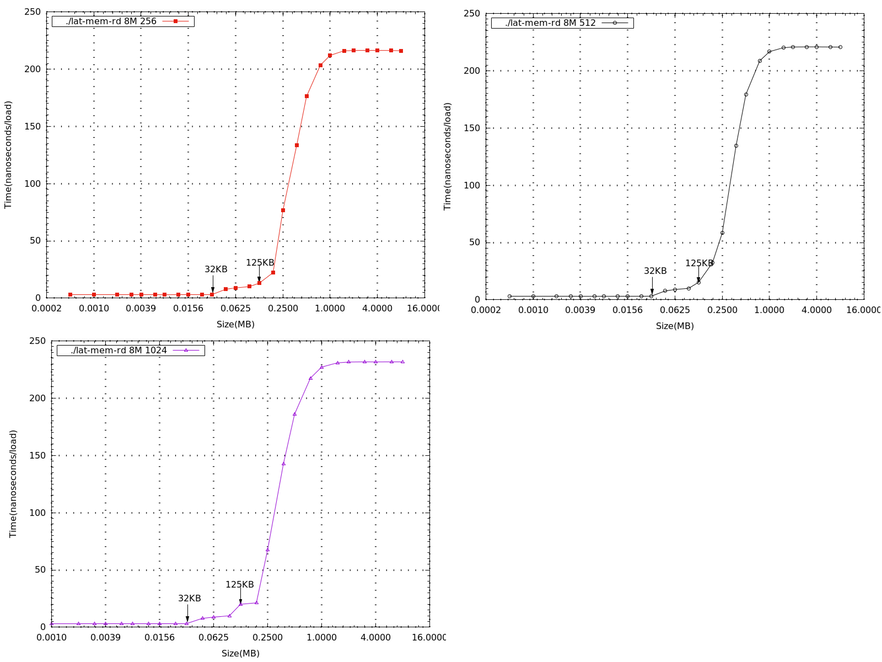
Linux Kernel 行為分析<工具篇>
------------------------------------------------
Ftrace
=================================================
- 簡介
- 第一手資料介紹
- 原文: https://www.kernel.org/doc/Documentation/trace/ftrace.txt
- Ftrace 是內建於Linux kernel的追蹤工具,從2.6.27 開始納入kernel主要發展版本。Ftrace被設計用來幫助系統開發者和系統設計者去知道kernel裡面發生甚麼事情。它可用於 debugging 或 分析 latencies and performance 發生在 user-space 之外的問題。
- 雖然ftrace通常被視為 function tracer,但它是其實是一個 framework 包含各式的 tracing 工具集。有 latency tracing以檢查 interrupts disabled 和 enabled 之間發生了甚麼,以及用於 preemption(搶占) 從task被喚醒的時間到實際task scheduled。
- 一個ftrace最常見用法是 event tracing。有幾百個 static event points 通過kernel 我們可以藉由enabled debugfs file system 去看到kernel中某些部份發生了甚麼事情
- 作者介紹
- Ftrace作者為在RedHat服務的 Steven Rostedt,主要目的是為Linux Kernel提供一個系統效能分析的工具,以便用以debug或是改善/優化系統效能,Ftrace為一個以Function Trace為基礎的工具,並包含了包括行程Context-Switch,Wake-Up/Ready到執行的時間成本,中斷關閉的時間,以及是哪些函式呼叫所觸發的,這都有助於在複雜的系統執行下,提供必要資訊以便定位問題
- Ftrace內的檔案 (/sys/kernel/debug/tracing)
- `/sys/kernel/debug/tracing`中,有些檔案是各個tracer共享使用的,有些是特定於某個tracer使用的。在操作這些檔案時,通常使用echo 來修改檔案的值,也可以在程式中通過讀寫相關的函數來操作這些檔案的值。下面只對部分檔案進行描述,詳細可以參考kernel中Documentation/trace 目錄下的檔案以及kernel/trace 下的source以了解其他文件的用途。(註: 請勿使用 vim 編輯器對這些檔案進行編輯)
- README
- 提供了一個簡短的使用說明,說明了ftrace 的操作方式。
- 可以通過`cat` 命令查看該文件以了解大概的操作流程。
- current_tracer
- 用於設定或顯示當前使用的tracer。
- 使用echo 將tracer名字寫入該文件可以切換到不同的tracer。
- 系統啟動後,其預設值為nop ,即不做任何trace操作。在執行完一段trace任務後,可以通過向該檔案寫入nop 來重置tracer。
- available_tracers
- 記錄了當前編譯進kernel的tracer列表,可以通過cat 查看其內容。
- 寫current_tracer 檔案時用到的tracer必須有列在available_tracers列表中。
- trace
- 提供了查看獲取到的trace訊息的port(輸出追蹤結果的地方,靜態)。
- 可以通過cat 查看該檔案以查看trace到的kernel活動記錄,也可以將其內容保存為記錄文件以備後續觀察。
- set_graph_function
- 設置要清晰顯示呼叫關係的函數,顯示的資訊結構類似於C 語言程式碼,這樣在分析kernel運作流程時會更加直觀一些。在使用function_graph tracer時使用。
- 預設為對所有函數都生成呼叫關係序列,可以通過寫該檔案來指定需要特別關注的函數。
- buffer_size_kb
- 用於設置單個CPU 所使用的trace buffer的大小。
- tracer會將trace到的資訊寫入buffer,每個CPU 的trace buffer是一樣大的。
- trace buffer為環形緩衝區的形式,如果trace到的訊息太多,則舊的訊息會被新的trace訊息覆蓋掉。
- 注意,要更改此檔案的值需要先將current_tracer 設置為nop 才可以。
- tracing_on
- 用於控制trace的暫停追蹤或繼續追蹤。
- 有時候在觀察到某些事件時想暫時關閉trace,可以將0 寫入該文件以停止trace,這樣trace buffer中比較新的部分是與所關注的事件相關的;寫入1 可以繼續trace。
- available_filter_functions
- 記錄了當前可以trace的kernel函數。對於不在該檔案中列出的函數,無法trace其活動。
- set_ftrace_filter 和 set_ftrace_notrace
- 在編譯kernel時配置了動態ftrace (選中CONFIG_DYNAMIC_FTRACE 選項)後使用。
- 如果一個函數名同時出現在這兩個文件中,則這個函數的執行狀況不會被trace。
- 注意,要寫入這兩個文件的函數名必須可以在文件available_filter_functions 中看到。預設為可以trace所有kernel函數,檔案 set_ftrace_notrace 的值則為空。
- events(資料夾)
- 可以監控的事件,例如writeback
- trace_options
- 控制輸出結果的資料量,也可修改追蹤器或事件的顯示資料方式
- Ftrace tracer 操作 : 使用
- 使用ftrace 提供的tracer來偵錯或者分析kernel時需要如下操作:
- 切換到目錄 /sys/kernel/debug/tracing/ 下
- 查看available_tracers ,獲取當前kernel支援的追蹤器列表
- 將所選擇的追蹤器的名字寫入current_tracer
- 通過將0 寫入tracing_on 來暫停追蹤訊息的記錄,此時追蹤器還在追蹤kernel的運行,只是不再向文件trace 中寫入追蹤信息
- 通過將0 寫入trace來刪除追蹤訊息的輸出
- 將要追蹤的函數寫入set_ftrace_filter ,將不希望追蹤的函數寫入set_ftrace_notrace。通常直接操作set_ftrace_filter 就可以了
- 激活ftrace 追蹤,即將1 寫入文件tracing_on。
- 如果是對應用程序進行分析的話,啟動應用程序的執行,ftrace 會追蹤應用程序運行期間kernel的運作情況
- 通過將0 寫入文件tracing_on 來暫停追蹤信息的記錄,此時追蹤器還在追蹤kernel的運行,只是不再向文件trace 中寫入追蹤信息
- 查看文件trace 獲取追蹤信息,對kernel的運行進行分析偵錯
- Ftrace on BeagleBone Black (ARM)
- 硬體平台: BeagleBone Black(BBB) Rev.C
- Core Architecture: ARM
- Core Sub-Architecture: Cortex-A8
- Silicon Core Number: AM335x 1GHz ARM® Cortex-A8
- 在BBB上安裝的Linux Kernel version: .config - Linux/arm 3.8.13 Kernel
- Rebuild kernel in BBB
- 由於我們要在BBB上使用Linux,因此在重編Kernel。
- 到kernel資料夾底下,重編指令,`make menuconfig ARCH=arm -j4`,即可進入config畫面
- 之後可以使用以下 tracer
- wakeup_rt
- wakeup
- irqsoff
- function
- Trace Event
- Ftrace 最常見用法是 event tracing
- 有幾百個 static event points 通過kernel 我們可以藉由enabled debugfs file system 去看到kernel中某些部份發生了甚麼事情
- debugfs默認是掛載在/sys/kernel/debug下,可以通過debugfs下的tracing/events查看各個event。
- 以下是跟scheduling相關的event
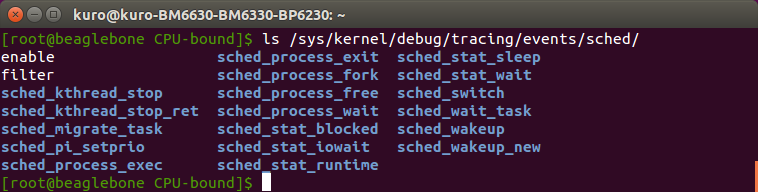
- 操作步驟範例
```
echo 0 > /sys/kernel/debug/tracing/tracing_on
echo 0 > /sys/kernel/debug/tracing/trace
echo nop > /sys/kernel/debug/tracing/current_tracer
echo 1 > /sys/kernel/debug/tracing/events/sched/enable
echo 0 > /sys/kernel/debug/tracing/events/syscalls/enable
echo 1 > /sys/kernel/debug/tracing/tracing_on
nohup chrt -r 90 ./matrix_mul &
pid1=$!
nohup chrt -r 90 ./matrix_mul &
pid2=$!
wait $pid1 $pid2
echo 0 > /sys/kernel/debug/tracing/tracing_on
cat /sys/kernel/debug/tracing/trace
```
- 結果
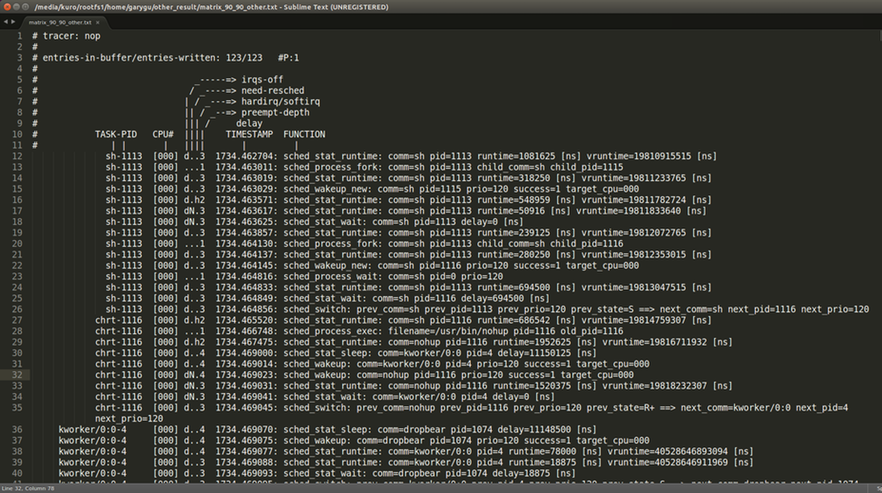
KernelShark
=================================================
- trace-cmd
- 他是user space front end command line tool for ftrace,有一些distribution將trace-cmd裝成package,就ubuntu 14.10來講,可以透過`apt-get install`安裝,裝完就可以使用了
.. code-block:: txt
$sudo apt-get install trace-cmd
```
$ sudo apt-get install trace-cmd
```
- trace-cmd 基本使用方式
- 簡單的方式就是先紀錄後報告
- 下面的這個指令是,enables the ext4 tracepoints for Ftrace,然後用record指令將ftrace data紀錄到trace.dat的檔案中,然後在透過report指令參數,讀取trace.dat的結果,然後輸出
.. code-block:: txt
```
root@garygu-Aspire-4830TG:~# trace-cmd record -e ext4
root@garygu-Aspire-4830TG:~# trace-cmd report
/sys/kernel/debug/tracing/events/ext4/filter
/sys/kernel/debug/tracing/events/*/ext4/filter
trace.dat.cpu0 trace.dat.cpu1 trace.dat.cpu2 trace.dat.cpu3
Kernel buffer statistics:
Note: "entries" are the entries left in the kernel ring buffer and are not
recorded in the trace data. They should all be zero.
CPU: 0
entries: 0
overrun: 0
commit overrun: 0
bytes: 444
oldest event ts: 12041.827184
now ts: 12041.829362
dropped events: 0
read events: 11
CPU: 1
entries: 0
overrun: 0
commit overrun: 0
bytes: 756
oldest event ts: 12041.826906
now ts: 12041.829397
dropped events: 0
read events: 19
CPU: 2
entries: 0
overrun: 0
commit overrun: 0
bytes: 604
oldest event ts: 12041.827041
now ts: 12041.829426
dropped events: 0
read events: 15
CPU: 3
entries: 0
overrun: 0
commit overrun: 0
bytes: 0
oldest event ts: 11939.099107
now ts: 12041.829453
dropped events: 0
read events: 0
CPU0 data recorded at offset=0x4ee000
4096 bytes in size
CPU1 data recorded at offset=0x4ef000
4096 bytes in size
CPU2 data recorded at offset=0x4f0000
4096 bytes in size
CPU3 data recorded at offset=0x4f1000
0 bytes in size
root@garygu-Aspire-4830TG:~# trace-cmd report
version = 6
CPU 3 is empty
cpus=4
trace-cmd-26790 [001] 12041.826906: ext4_journal_start: dev 8,1 blocks, 35 rsv_blocks, 0 caller __ext4_new_inode+0x595
trace-cmd-26790 [001] 12041.826941: ext4_mark_inode_dirty: dev 8,1 ino 26214438 caller ext4_ext_tree_init+0x3a
trace-cmd-26790 [001] 12041.826949: ext4_mark_inode_dirty: dev 8,1 ino 26214438 caller __ext4_new_inode+0xff1
trace-cmd-26790 [001] 12041.826952: ext4_allocate_inode: dev 8,1 ino 26214438 dir 26214401 mode 0>o<
trace-cmd-26790 [001] 12041.826955: ext4_es_lookup_extent_enter: dev 8,1 ino 26214401 lblk 0
trace-cmd-26790 [001] 12041.826956: ext4_es_lookup_extent_exit: dev 8,1 ino 26214401 found 1 [0/1) 10486
```
- KernelShark
- kernelshark是trace-cmd的前端讀取工具,他專門讀取trace.dat的資料,然後將結果用圖形化的方式呈現出來,他預設讀取檔案就是trace.dat,然後這個kernelshark也是ubuntu可以安裝的套件,裝完就可以使用了,只需要下達`kernelshark`就可以自動讀取trace.dat的資料,然後圖示化結果
- 下圖就是將上面trace ext4的結果,圖像畫出來
.. code-block:: txt
$sudo apt-get install kernelshark
```
$ sudo apt-get install kernelshark
```
.. image:: /embedded/arm_linux/kernelshark_ext4.png
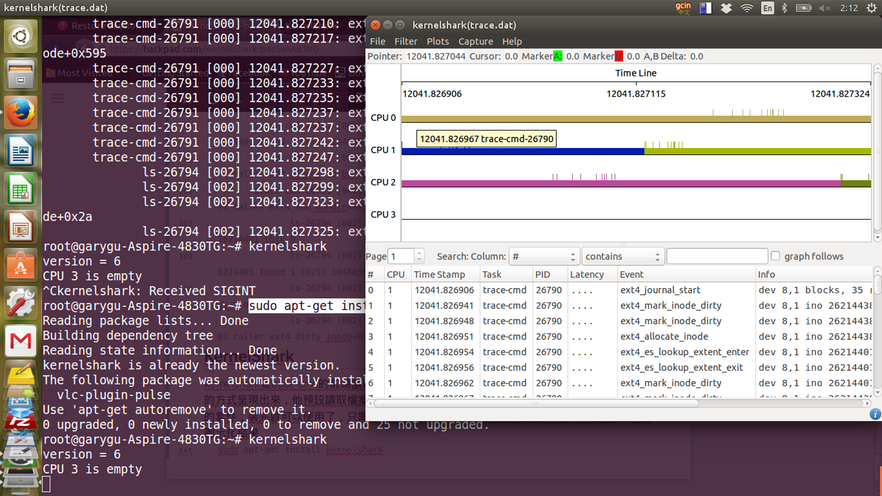
Ftrace和Trace-cmd + KernelShark 綜合使用方式
=================================================
- event tracer: 當需要對對特定事件去觀察時, 使用event tracer較能看出事件發生的影響. 而且只trace特定事件, tracer開啟時對於系統效能的影響較小
- 使用方式:
.. code-block:: txt
```
mount -t debugfs debugfs /sys/kernel/debug/
cd /sys/kernel/debug/tracing
cat available_events (列出目前能使用的event)
echo "irq==21" > events/irq/irq_handler_entry/filter (設定irq_handler_entry事件的 filter條件)
echo "irq==21" > events/irq/irq_handler_exit/filter (設定irq_handler_exit事件的 filter條件)
echo 1 > events/irq/irq_handler_entry/enable (開啟irq_handler_entry event)
echo 1 > events/irq/irq_handler_exit/enable (開啟irq_handler_entry event)
cat available_events # 列出目前能使用的event)
echo "irq==21" > events/irq/irq_handler_entry/filter # 設定irq_handler_entry事件的 filter條件
echo "irq==21" > events/irq/irq_handler_exit/filter # 設定irq_handler_exit事件的 filter條件
echo 1 > events/irq/irq_handler_entry/enable # 開啟irq_handler_entry event
echo 1 > events/irq/irq_handler_exit/enable # 開啟irq_handler_entry event
```
- trace-cmd + kernelshark: 利用trace-cmd擷取trace資料並用kernelshark圖形化表示
- 以trace-cmd record持續紀錄trace data
- ./trace-cmd record -e irq_handler_entry -f "irq==21" -e irq_handler_exit -f "irq==21"
- 按ctrl + c 中止紀錄
- 使用kernelshark載入trace.data
Linux Kernel Timer Interrupt
------------------------------------------------
Linux Timer Interrupt 理論
=================================================
- Timer在Linux Kernel的例子
- 當我們有一陣子不使用電腦的時候,這時候螢幕會關掉,或是我們收到系統來的警告,要求刪除一些長久沒有使用的檔案,這是怎樣的機制?
- 要能做到上述這些事情,是因為timer允許kernel追蹤我們使用滑鼠和鍵盤的時間,或是記錄距離現在最近一次的使用時間(timestamp),這是timestamp就要透過kernel去紀錄
- 環境
- qemu模擬下,armv7的環境
- OS: linux 3.16.0-23-generic
- timer interrupt frequency : 300 HZ
- 紀錄時間的是透過linux kernel裡面的變數叫做`jiffies`,透過這個變數去紀錄從系統開機後到現在所累積的timer interrupt次數,然後這個次數是根據中斷的發生而增加
- Timer interrupt 的用處在於
#. 在規定的時間範圍到達時執行指定的function
#. 更新日期,時間,和系統開機到目前經過的時間
#. 更新系統資源使用率統計
#. 檢查目前的所在執行的process是否超過它原本給定的額度,如果是的話,則preempt這個process讓其他程序執行(process switch)
#. 檢查軟體中斷(alarm 系統呼叫),跟時間延遲的函式(delay function),其延遲時間是否已經超過
#. 檢查軟體時間器(alarm 系統呼叫),跟時間延遲的函式(delay function),其延遲時間是否已經超過
- 紀錄時間的是透過linux kernel裡面的變數叫做`jiffies`,透過這個變數去紀錄從系統開機後到現在所累積的timer interrupt次數,然後這個次數是根據中斷的發生而增加,另外硬體也定義了一個週期(一個timer interrupt)大概是多少時間,我們可以透過兩個方法找到這個周期定義:
.. code-block:: txt
$garygu@garygu-Aspire-4830TG:/usr/src/linux-headers-3.16.0-37-generic$ sudo make menuconfig
- 如上所示,到這個資料夾底下,下達 $sudo make menuconfig,可以看到圖形化的menuconfig,依照選單選擇Processor type and features ----> Timer frequency (250HZ),就可以找到,因為我們的環境下沒有這個設定檔,所以我就先拿自己的電腦測試
- 另外還有一種作法可以透過/proc/interrupts這個檔案去trace間隔 1 秒的時間那,timer interrupt做了幾次
- 透過這個檢測,可以知道這個linux kernel預設的timer interrupt頻率為300HZ,所以推算出一個timer interrupt所需時間為3.33毫秒
以上這些方法,都是參考`Adrian's Blog <http://adrianhuang.blogspot.tw/2007/10/linux-kernel-hz-tick-and-jiffies.html>`_
Linux Timer Interrupt 實作
=================================================
- 在剛架設好的qemu模擬的ARMv7環境,去trace timer interrupt
- 下達`trace-cmd`指令
- 在bbb上編譯安裝trace-cmd和kernelshark,為了方便觀看ftrace的event,目前已經成功安裝trace-cmd,但是在編譯gui的kernelshark的過程有出現一些問題,先是遇到`error: operator '<' has no left operand`看了一下出錯的檔案,錯誤發生在`#if GTK_VERSION < CALC_GTK_VERSION(2,18,0)`看來是GTK_VERSION沒有值,所以我直接手動輸入,雖然最後正確編譯完成但是當我要執行`kernelshark`的時候遇到了`(kernelshark:7179): Gtk-WARNING **: cannot open display:`,另外編譯過程也一直出現`awk:cmd. line:1: Math support is not compiled in`,所以目前還是先在host端用kernelshark看trace-cmd的結果
.. code-block:: txt
$sudo trace-cmd record -e all
- 這時資料輸出到trace.dat,在將檔案移到我本地端的電腦執行kernelshark,可以看到如下圖,先fliter掉其他task和event只觀察timer event,irq event,然後我先挑一個cpu來觀察CPU0,先行分析
另外硬體也定義了timer interrupt 的週期大概是多少時間,我們可以透過兩個方法找到這個周期定義:
```
$ sudo make menuconfig
```
.. image:: /embedded/arm_linux/kernelshark_timer event.png
- 可先至<理論篇> 先了解linux kernel的timer interrupt的運作,再搭配圖示
- 從kernelshark下面list中的event info可以看到
- event info
- irq_handler_entry irq=34 name=timer
- softirq_raise vec=1 [action=TIMER]
- irq和vec的號碼代表的是什麼?
- irq的號碼就是註冊硬體IRQ的編號
- vec號碼,就是註冊softirq的號碼,這個延遲任務是timer
- 如上所示,到這個資料夾底下,下達 $sudo make menuconfig,可以看到圖形化的menuconfig,依照選單選擇Processor type and features ----> Timer frequency (250HZ),就可以找到,因為我們的環境下沒有這個設定檔,所以我就先拿自己的電腦測試
- Timer Interrupt Frequency
在看timer interrupt在kernel內部的活動之前,要先了解timer interrupt在kernel的設置頻率為何?
- 另外還有一種作法可以透過/proc/interrupts這個檔案去trace間隔 1 秒的時間內timer interrupt的次數變化,就可以知道timer interrupt frequency
- 首先可以從/proc/interrupts的檔案裡頭,看到irq的紀錄,可以透過,也可從中看到是哪個CPU在負責哪些中斷請求
.. code-block:: txt
```
cat /proc/interrupts
CPU0
34: 38623561 GIC 34 timer
36: 0 GIC 36 rtc-pl031
37: 6126 GIC 37 uart-pl011
41: 170945 GIC 41 mmci-pl18x (cmd)
42: 932753 GIC 42 mmci-pl18x (pio)
44: 8 GIC 44 kmi-pl050
45: 113 GIC 45 kmi-pl050
47: 688 GIC 47 eth0
IPI0: 0 CPU wakeup interrupts
IPI1: 0 Timer broadcast interrupts
IPI2: 0 Rescheduling interrupts
IPI3: 0 Function call interrupts
IPI4: 0 Single function call interrupts
IPI5: 0 CPU stop interrupts
IPI6: 0 IRQ work interrupts
IPI7: 0 completion interrupts
Err: 0
- 可以透過/proc/interrupts這個檔案去trace間隔 1 秒的時間那,timer interrupt做了幾次
.. code-block:: txt
```
```
root@jared14-5480:/# cat /proc/interrupts | grep timer && sleep 1 && cat /proc/interrupts | grep timer
34: 62118555 GIC 34 timer
34: 62118857 GIC 34 timer
```
所以我們就可以知道在這1秒的時間內做了幾次timer interrupt了,而這個可以得知,kernel設置timer interrupt的頻率為300HZ,所以執行一次timer interrupt的時間為3.33毫秒
- 但是透過上述這個方法在bbb上測試,結果差距很大,有時候測出來的頻率為21hz,有時是500hz,timer interrupt的頻率相當不固定,這是因為linux kernel希望在idle的時候做少一點事情,可以達到省電的效果,所以設計了這種動態調整timer interrupt frequency的機制
- 透過這個檢測,可以知道這個linux kernel預設的timer interrupt頻率為300HZ,所以推算出一個timer interrupt所需時間為3.33毫秒
.. code-block:: txt
以上這些方法,是參考[Adrian's Blog ](http://adrianhuang.blogspot.tw/2007/10/linux-kernel-hz-tick-and-jiffies.html)
Tickless OS的補充
就是讓kernel的timer interrupt頻率不固定,一般的timer interrupt frequency都會在編譯階段設定好,但是linux kernel希望能做到在idle階段做少一點事 情,也能夠省電,所以有了tickless的機制,也就是這個timer interrupt的頻率是動態調整的,想要有這個功能就必須在編譯kernel的時候勾選`NO_HZ`,在menuconfig中的 ->General setup ->Timer subsystem -> Tickless System (dynamic Ticks),而我們的beaglebone就是設置了這個Tickless System,才使得每次測出來的timer interrupt頻率不相同
Linux Timer Interrupt 實作
=================================================
- Timer Interrupt Frequency
如果從ftrace得到的資料看來
- 我們可以從kernelshark的結果圖中,選定兩個連續的timer irq計算時間差,可以得知做一次timer interrupt的周期,所以我抓了連續做了13次的timer interrupt的起始時間和終止時間,取其平均,看其大致的timer interrupt的周期為何?
- 看其中一個等待要被執行的function,如圖中的`pm_suspend_timer_fn`,不過不可從這裡開始算,因為這只是timer的初始化,還沒有timer interrupt,所以我們應該是從接下來的第一個timer interrupt開始紀錄(橘色標起部份),故為`9910.799628`開始第一次timer interrupt
- 但是透過上述這個方法在bbb上測試,結果差距很大,有時候測出來的頻率為21hz,有時是500hz,timer interrupt的頻率相當不固定,這是因為linux kernel希望在idle的時候做少一點事情,可以達到省電的效果,所以設計了這種動態調整timer interrupt frequency的機制
.. image:: /embedded/arm_linux/timer interrupt frequency_01.png
```
Tickless OS的補充
就是讓kernel的timer interrupt頻率不固定,一般的timer interrupt frequency都會在編譯階段設定好,但是linux kernel希望能做到在idle階段做少一點事 情,也能夠省電,所以有了tickless的機制,也就是這個timer interrupt的頻率是動態調整的。
想要有這個功能就必須在編譯kernel的時候勾選`NO_HZ`,在menuconfig中的 ->General setup ->Timer subsystem -> Tickless System (dynamic Ticks),而我們的beaglebone就是設置了這個Tickless System,才使得每次測出來的timer interrupt頻率不相同
```
一直到第13個timer interrupt結束,所以我就是找到第14個timer interrupt的觸發點,表示第13個timer interrupt結束的時間,故為`9910.851424`
- 在架設好的qemu模擬的ARMv7環境,去trace timer interrupt
- 下達`trace-cmd`指令,去紀錄從現在開始kernel內部的所有event活動
```
$ sudo trace-cmd record -e all
```
.. image:: /embedded/arm_linux/timer interrupt frequency_02.png
- 這時資料輸出到trace.dat,在將檔案移到我本地端的電腦執行kernelshark,可以看到如下圖,先fliter掉其他task和event只觀察timer event,irq event,然後我先挑一個cpu來觀察CPU0,先行分析
所以我們就可以算出一個大概的timer interrupt周期
(9910.851424 - 9910.799628) / 13 = 0.003984秒,也就是3.984毫秒,跟我們透過/proc/interrupt中看到的頻率有一些誤差
event.png
- 可先至<理論篇> 先了解linux kernel的timer interrupt的運作,再搭配圖示
- 從kernelshark下面list中的event info可以看到
- event info
- irq_handler_entry irq=34 name=timer
- softirq_raise vec=1 [action=TIMER]
- irq和vec的號碼代表的是什麼?
- irq的號碼就是註冊硬體IRQ的編號
- vec號碼,就是註冊softirq的號碼,這個延遲任務是timer
- Timer Interrupt Flow
- 所以從圖像化出來的list我們可以知道,timer interrupt的順序如下,依照event
#. timer_init,初始化timer,不同的function執行,會用不同的位置紀錄
#. timer_start,這是開始計時,和這個function他的expiration time時,他還有紀錄要執行這個function要等多少次timer interrupt,如果到達這個expiration time就會執行這個function
#. irq_handler_entry,timer interrupt, irq號碼是34
#. softirq_raise,因為通常不希望硬體中斷花太常時間,所以會希望由softirq來執行,這個event是指派要處理timer interrupt的action 到softirq_vec中
#. irq_handler_exit,硬體中斷離開
#. softirq_entry,開始執行延遲任務,開始執行剛剛指派處理timer的action,timer interrupt 加 1
#. timer_cancel,停止timer
#. timer_expire_entry,表示預計執行指令的時間到了
#. timer_expire_exit
#. softirq_exit,延遲任務執行結束,然後再下一個timer interrupt
- timer interrupt flow chart
.. image:: /embedded/arm_linux/timer_interrupt.png
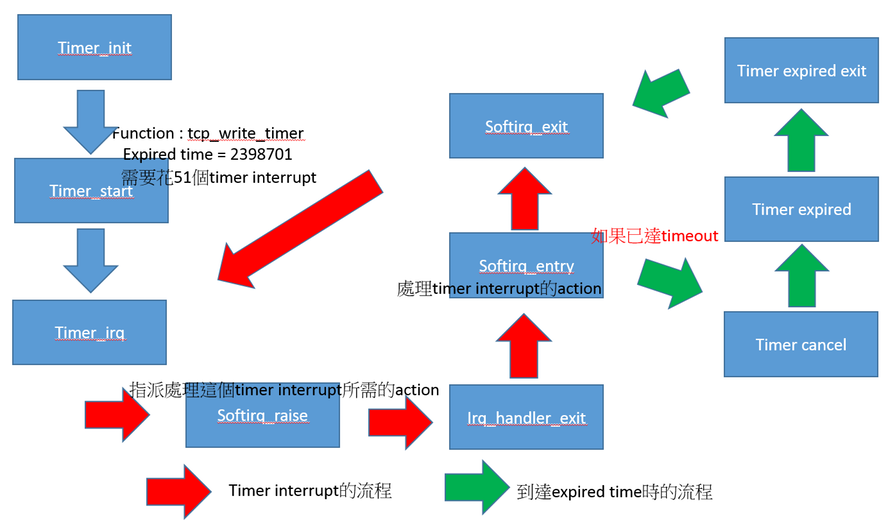
- 所以我們就可以透過這個timer interrupt的流程,搭配trace出來的資料,知道不同function被觸發或是執行的時間長度了
- 可以拿一個task所執行的function來看
- task : sshd , function : tcp_write_timer
.. image:: /embedded/arm_linux/timer interrupt task timer.png
interrupt task timer.png
從這邊可以看到要執行這個function,必須要等到51個timer interrupt之後才可以執行,所使用的timer位置是在`0xee57a390`
Linux Scheduler 行為分析
------------------------------------------------
Linux Scheduler 理論
=================================================
- 藉由CPU在不同行程之間的轉換,作業系統可以讓電腦的產量提高。
- 在單一處理器系統中,同一時間只能有一個Process在執行,其他都必須等待直到CPU有空,才能接著重新排班。
- 排班(scheduling)的工作是在OS之中分配CPU時間給不同任務(task)使用
- CPU-I/O 分割週期
- CPU排班的重點在於:行程的執行是由CPU執行的時間及 I/O 等待時間所組成的週期(cycle),行程在這兩個狀態之間交替往返。
- 行程執行由一個CPU分割(CPU burst)開始,接著一個 I/O burst,然後再另一個CPU burst,再來又一個 I/O burst ,最後一個CPU burst結束時,同時會有一個系統 要求中止執行這個 task,如下圖所示。
.. image:: /embedded/arm_linux/alternating sequence of cpu and io bursts.png
sequence of cpu and io bursts.png
- CPU burst 的持續時間可被大量的量測,會大致上類似下圖的頻率曲線所示,這個曲線一般是指數型或超指數型 (hyperexponential)
- 短的CPU burst很多,長的CPU burst則很少。
- I/O bound 的程式之中一般是很多很短的 CPU burst;CPU bound 的程式就會有一些非常長的CPU burst
- 所以根據不同種類的程式選取適當的 CPU排班演算法是非常重要的
.. image:: /embedded/arm_linux/histogram of cpu_burst durations.png
of cpu_burst durations.png
- CFS (完全公平排班器,Completely Fair Scheduler)
- 在Linux kernel 2.6版以後引進
- 可參考Linux Kernel 3.0.4中有關CFS的Design文件 (路徑在Documentation/scheduler/sched-design-CFS.txt)
- 作者試著用一句 “CFS basically models an “ideal, precise multi-tasking CPU” on real hardware.” 來簡要說明CFS 80%設計精神
- 所謂理想的多工處理器,就是當處理器有100%的能力,且系統中有兩個Tasks正在運作,這兩個Tasks可以各自取得處理器50%的執行能力,並被處理器平行執行,也就是說任意時間間隔來看(例如,隨機取10ms間隔),這兩個Tasks都是分配到處理器50%的執行能力.
- 因為在實際的機器上,一次只會執行一個task,所以就必須介紹一下`virtual runtime`的概念,他表示你這個task被CPU執行了多久了
- 因為CFS的宗旨是在理想的情況下,希望每個task都能夠被公平的執行,所以照裡來說,每個task的virtual runtime要是相同的,但是事實上不可能是這樣的,一定友人執行的多友人執行的少,為了要balance每個task的執行時間,所以每次在挑task執行時,都會去找virtual runtime最小的task來執行,上述是CFS的理想設計理念,但是也是有跳脫這個基本設計理念的,想是nice levels , multiprocessing , and various algorithms
- 既然要挑最少被執行的task,那要怎麼紀錄每個task的執行時間 ?這邊linux kernel是使用time-ordered `rbtree` data structure去maintain這些資料,這個資料結構的特性是愈左邊的結點runtime愈少,愈右邊就是執行的比較久的task,所以CFS就會去找leftmost的task起來做
- 大體而言,CFS的執行過程是
#. TASK執行一陣子後被scheduler switch out
#. 這時就會總結執行的時間到這個task的virtual runtime
#. 一旦這個task他總共所執行的時間大於了另一個task的virtual runtime,這時候就是那個task成為rbtree中leftmost task
#. 所以這時候就會preempt掉目前正在執行的task,換執行這一個新的leftmost的task
- 傳統的Unix行程排班器會給行程固定的 time-slice,但高優先權的行程比低優先權的行程先執行
- CFS引進新的排班演算法叫做公平排班(fair scheduling)
- 取代傳統固定time-slice,所有的行程被配置一定比例的行程時間
- CFS計算根據一個全部可執行行程的函數計算出一個行程該執行多久
- 一開始,假如有N個可執行的行程,CFS讓每一個行程分配處理器的 1/N時間
- 然後CFS根據每個行程的nice值加權該行程的分配量以調整其分配量
- 使用預設的nice值之行程的加權值是1,優先權不會改變
- 有較小nice值的行程(較高優先權)接收到較高的加權值,而較大nice值的行程(較低優先權)接收到較低的加權值。
- 然後CFS對每一個行程以正比於行程加權值,除以所有可執行行程之總加權值的「time-slice」執行
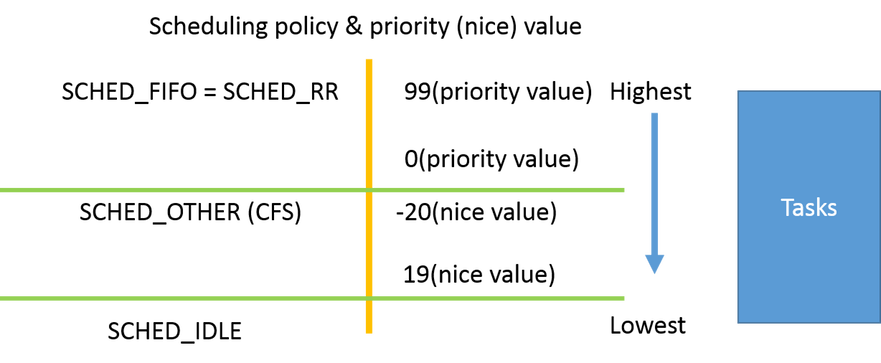
Linux Scheduler 實作
=================================================
- 重編Kernel,讓環境單純化,才會比較符合理論值
- 關掉 SMP
- 關掉SMP的功能,因為BBB是單核心,不需要這個功能,會影響效能
- 高解析度計時器
- 高解析度計時器的解析度為1 ns
- 關掉休眠(省電)機制
- 由於kernel內建休眠機制,這會導致在執行程式時,CPU顯現之效能會隨時間不一致
根據理論篇,我們想撰寫CPU-bound和IO-bound程式,在不同的排程策略(FIFO, RR)下和給定不同的優先權下,程式會如何執行
- 環境
- BeagleBone Black(BBB) Rev.C
- Linux Kernel version: 3.8.13
- 指令
- 使用如下指令,可以改變排程策略(-f : FIFO, -r : RR),指定優先權(EX:90,45)
- CPU-bound
- 做的是矩陣相乘的動作,複雜度為O(n^3)
- 分別測試`fifo` , `rr` scheduling policy,主要是看不同scheduling policy下和不同優先權的`time slice`給定方式和行為
- 圖示: 橫軸 : 第幾次switch , 蹤軸 : 這一次switch的time slice
- fifo : 優先權分別為90 90
.. code-block:: txt
```
chrt -f 90 ./../CPU-bound/matrix_mul &
chrt -f 90 ./../CPU-bound/matrix_mul &
```
.. image:: /embedded/arm_linux/sched_cpu_fifo_90_90.png

初步觀察,fifo policy的time slice給定差異頗大,而且可見兩個process的執行相當不公平,不過還是可以看到前面的幾次交替還是有給後進來的process執行的機會
- fifo : 優先權分別為90 45
.. code-block:: txt
```
chrt -f 90 ./../CPU-bound/matrix_mul &
chrt -f 45 ./../CPU-bound/matrix_mul &
```
.. image:: /embedded/arm_linux/sched_cpu_fifo_90_45.png

- rr : 優先權分別為90 90
.. code-block:: txt
```
chrt -r 90 ./../CPU-bound/matrix_mul &
chrt -r 90 ./../CPU-bound/matrix_mul &
```
.. image:: /embedded/arm_linux/sched_cpu_rr_90_90.png
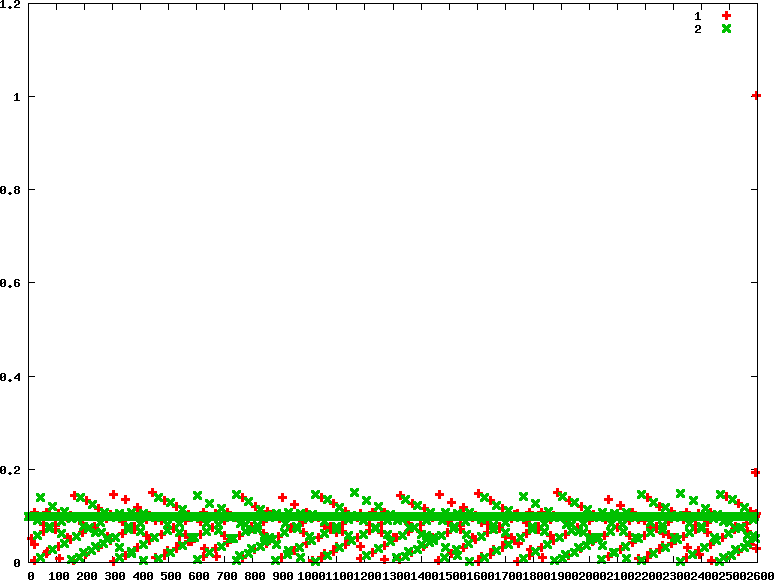
初步觀察rr policy,兩個process所分配到的time slice執行時間較為相近
另外我們可以從linux kernel原始碼中,看到預設的time slice給定是100 msecs,跟我們測出來的結果,大致符合!
.. code-block:: txt
```
/*
* default timeslice is 100 msecs (used only for SCHED_RR tasks).
* Timeslices get refilled after they expire.
*/
#define RR_TIMESLICE (100 * HZ / 1000)
```
- rr : 優先權分別為90 45
.. code-block:: txt
```
chrt -r 90 ./../CPU-bound/matrix_mul &
chrt -r 45 ./../CPU-bound/matrix_mul &
```
.. image:: /embedded/arm_linux/sched_cpu_rr_90_45.png
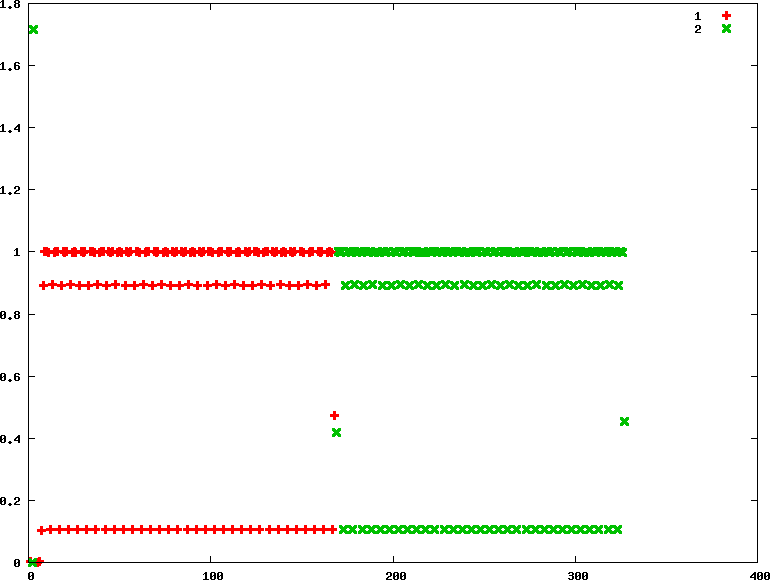
從圖上看來很不公平,不像RR比較像FIFO。
推測是給定不同優先權的關係,Linux直接以FIFO進行排班
- IO-bound
- 做的是讀檔和寫的動作
- 分別測試`fifo` , `rr` scheduling policy,主要是看不同scheduling policy下和不同優先權的`time slice`給定方式和行為
- 圖示: 橫軸 : 第幾次switch , 蹤軸 : 這一次switch的time slice
- IO- BOUND的time slice都相當的短跟CPU-bound比起來
- fifo : 優先權分別為90 90
.. image:: /embedded/arm_linux/sched_io_fifo_90_90.png
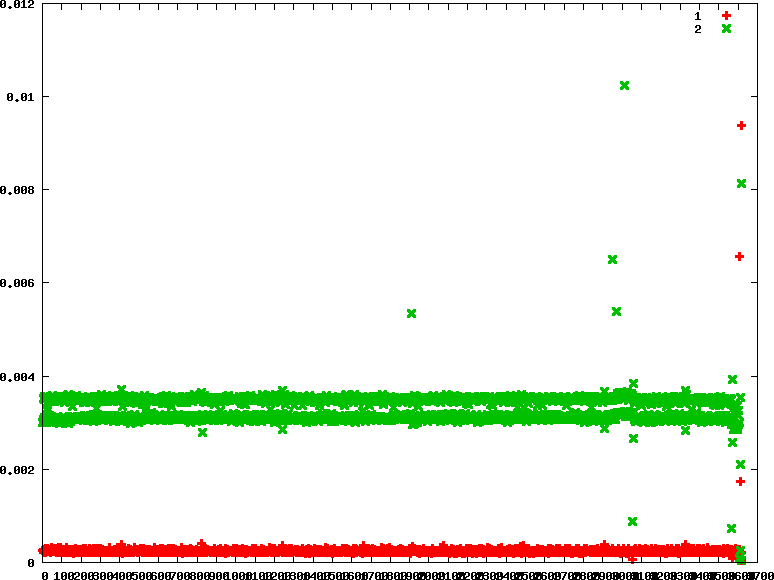
從fifo policy中,還是可以觀察兩個process還是有一直切換的,主要是因為在做IO過程是需要等待的,那在等待的過程中,linux 作業系統就會切換工作
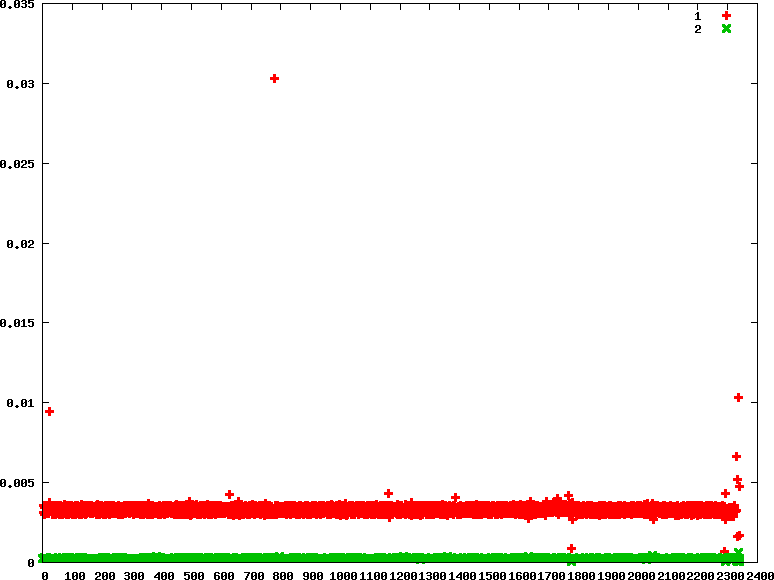
- fifo : 優先權分別為90 45
.. image:: /embedded/arm_linux/sched_io_fifo_90_45.png
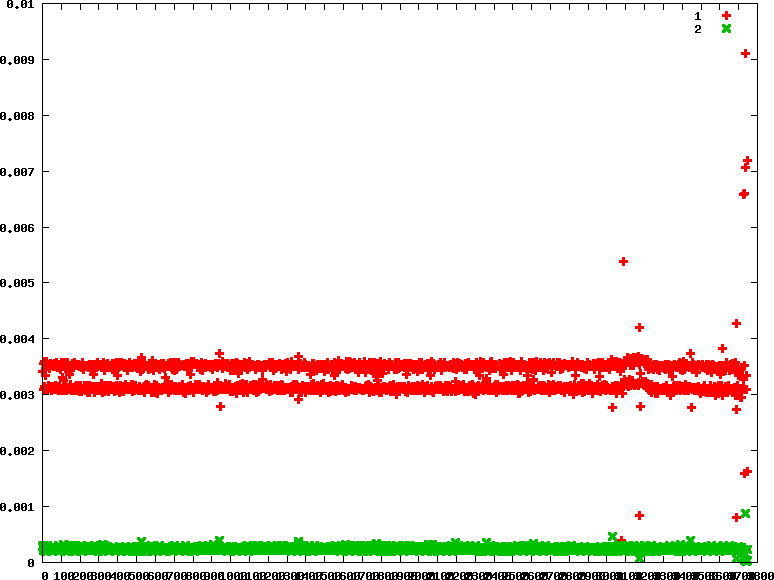
- rr : 優先權分別為90 90
.. image:: /embedded/arm_linux/sched_io_rr_90_90.png
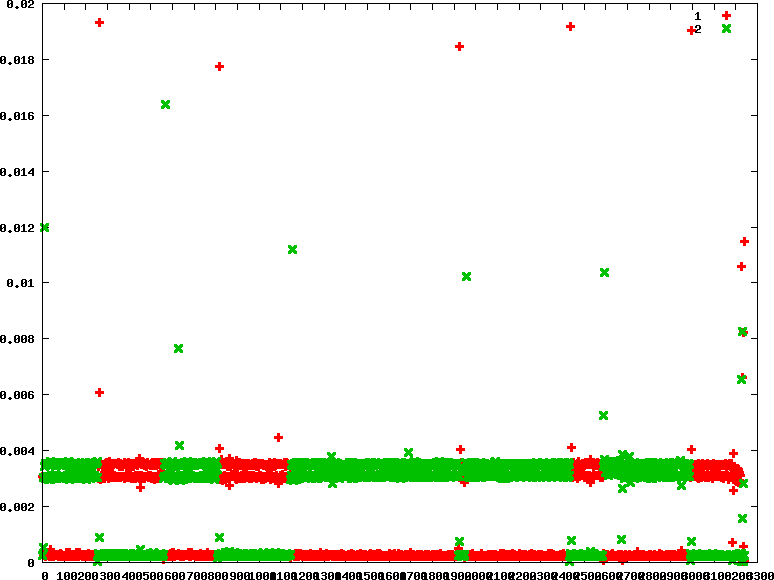
- rr : 優先權分別為90 45
.. image:: /embedded/arm_linux/sched_io_rr_90_45.png
Linux kernel scheduling CFS trace event
=================================================
- 驗證CFS行為
- 下圖因為綠色覆蓋在紅色之上所以看不太出來是交替執行,可參考下下圖可知兩個task以極短執行時間交互運行
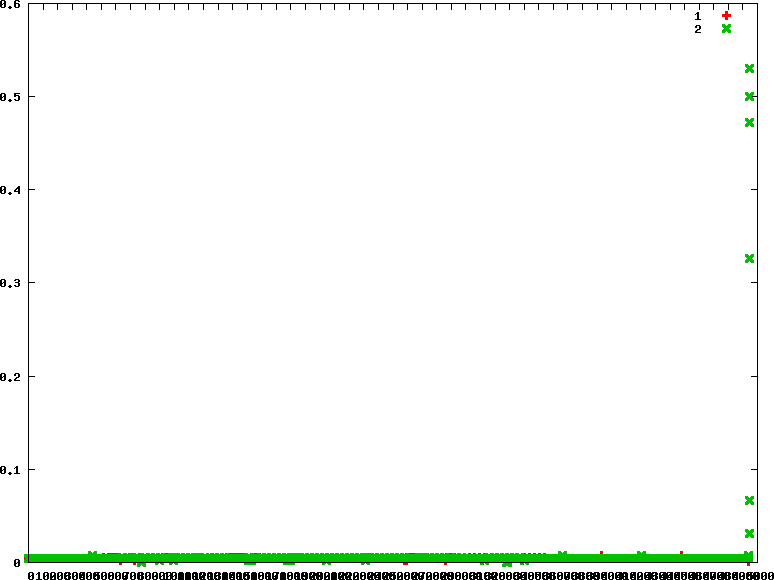
自動化測試工具
------------------------------------------------
[Source Code ](https://github.com/hkuro/ARM-Linux_performance_analysis)
- 前置作業
- 詳情請見 [Hackpad ](https://hackpad.com/Install-gnuplot-on-the-beaglebone-black-oCP8XM60OC5)
- 安裝lmbench
```
git clone https://github.com/el8/lmbench-next.git
cd lmbench-next
make ARCH=arm CROSS_COMPILE=arm-linux-gnueabi-
```
- 主程式為 auto 執行檔,藉由編譯auto.c 而來
- 程式流程圖如下
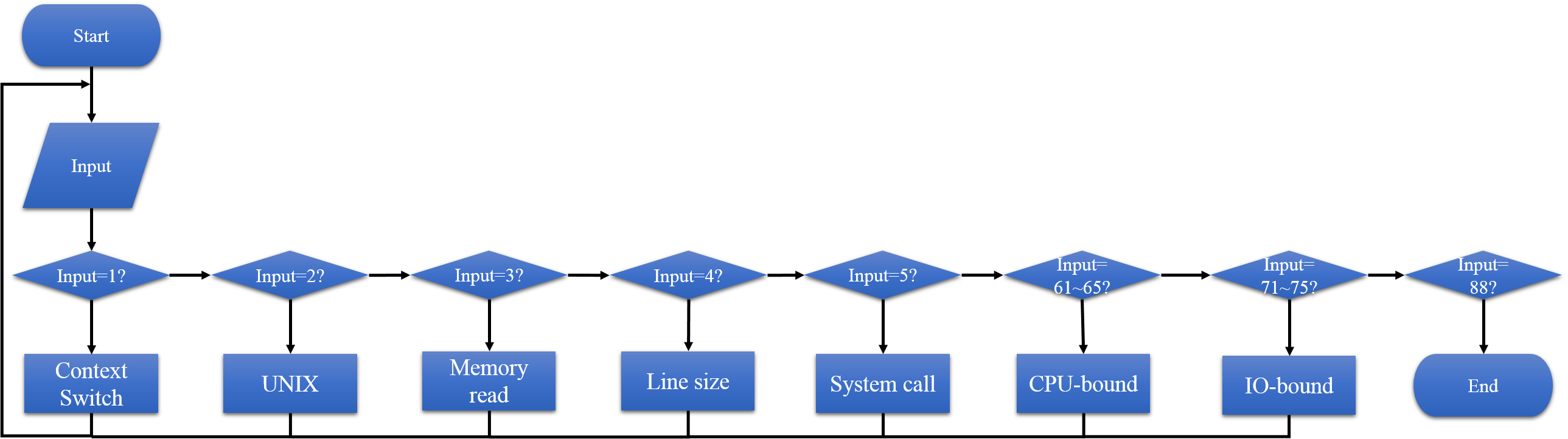
- 若是使用lmbench 中的指令來分析,則可以在``AUTO_TEST/lmbench-next/AUTO_TEST/`` 中找到相對應的results 目錄,裡面會存放著結果原始檔與其畫出的圖表。
- 每次選擇一項功能後,會使用lmbench 對應的執行檔輸出原始資料到results 目錄下,並且在使用gnuplot對其畫出圖表,幫助使用者分析。
- 若是使用Ftrace 進行 Linux-scheduling 分析,則可以在``AUTO_TEST/CPU-bound 和 AUTO_TEST/IO-bound`` 中找到相對應的results 目錄,裡面會存放著結果原始檔與其畫出的圖表。
- 每次選擇一項功能後,會使用Ftrace 對應的腳本檔輸出原始資料到results 目錄下,並且在使用gnuplot對其畫出圖表,幫助使用者分析。
- 分析內容依照類別可分為:
- CPU-bound / IO-bound
- CFS / RR / FIFO
- 權限相同(90/90) / 權限不同(90/45)
Q & A
------
* ARM-Linux Q & A : `hackpad <https://embedded2015.hackpad.com/QA-ARM-Linux-YNnKlrWkbeU>`_
* ARM-Linux Q & A : [hackpad ](https://embedded2015.hackpad.com/QA-ARM-Linux-YNnKlrWkbeU)
