embedded/f9-kernel
- About Microkernel
- L4 microkernel
- Memory pool
- Flexible pages(fpage)
- Address space(AS)
- Context Switch
- IRQ Handler
- Flash Patch and Breakpoint Unit (FPB), ARMv7-M Debug Architecture
- MPU (Memory Protection Unit)
- Message Register
- MapItem
- GrantItem
- CtrlXferItem
- StringItem
- Buffer Register
- IPC 過程
- T_SEND_BLOCKED & T_RECV_BLOCKED
- 使用 L4 IPC
- Context
- User-level Thread Control Block
- Thread Create
- Thread Initialization
- Thread start過程
- Root Thread
- KProbe
- Debug Handler
- Example – sampling
- How-to Use KTimer
- Kernel Interface Page
- Init Hook
- KTable
- KDB(in-kernel debugger)
- Troubleshooting
| title: F9 microkernel categories: embedded, arm, stm32, stm32f4, microkernel toc: yes …最後一個delta = 0的event |
|---|
| * 廖健富 / Rampant1018 * 鄒宗延 / slpbaby / yan(wiki) * 詹凱傑 / bpotatog |
| * 共筆 / Hackpad |
| Overview |
About Microkernel
在計算科學領域中,microkernel(μ-kernel)指的就是集合一些精簡的軟體,而這些軟體可以提供實作作業系統的機制,例如:地址空間(Address Space, AS)管理、執行緒(thread)管理、行程間通訊(Inter-Process Communication, IPC)。如果硬體或是CPU有提供不同的執行模式,則μ-kernel就是執行在權限最高的部份,例如ARM的handle mode。
- Basic Idea
傳統的作業系統核心(monolithic)會提供大部分的服務,像是UNIX-like的系統都有一些典型的階層架構,示意圖如下:
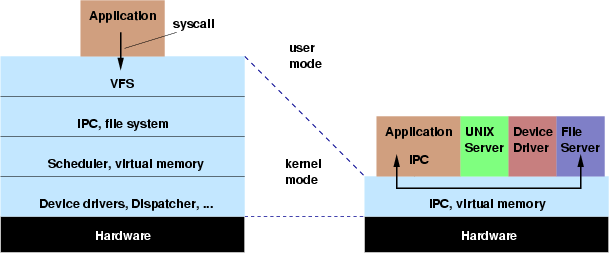
一個μ-kernel的概念則是盡可能的縮小核心,並將系統服務移到kernel外,而在這種系統中會使用IPC去呼叫服務。
優點
- 會有比傳統核心要小的Trusted Computing Base(TCB)。Trusted Computing Base,系統中的一部分,可以通過他自己的安全方針,因此一個安全的系統操作依賴正確的TCB架構。
- 只要增加一些服務就能簡單的擴充
- 可以被高度的調整,針對不同的server實作不同的服務,不需要就移除
- 支援軟體工程技術,user-mode的程式會執行在自己的address space下,只能透過定義好的IPC界面被使用,實現軟體封裝
- 提供fault isolation,一個發生錯誤的元件只會造成他自己的AS錯誤,不會影響其他的元件
- 挑戰
- 因為所有的系統服務都是透過IPC呼叫,所以IPC是整個系統的效能關鍵之一,事實上μ-kernel-based的系統在呼叫系統服務上的overhead會大於傳統系統,μ-kernel based的系統需要四個mode的切換以及兩次完整的context switch;傳統系統只需要兩個mode切換且不需要context switch。設計並且實作μ-kernel的挑戰就在盡力降低IPC的overhead上。
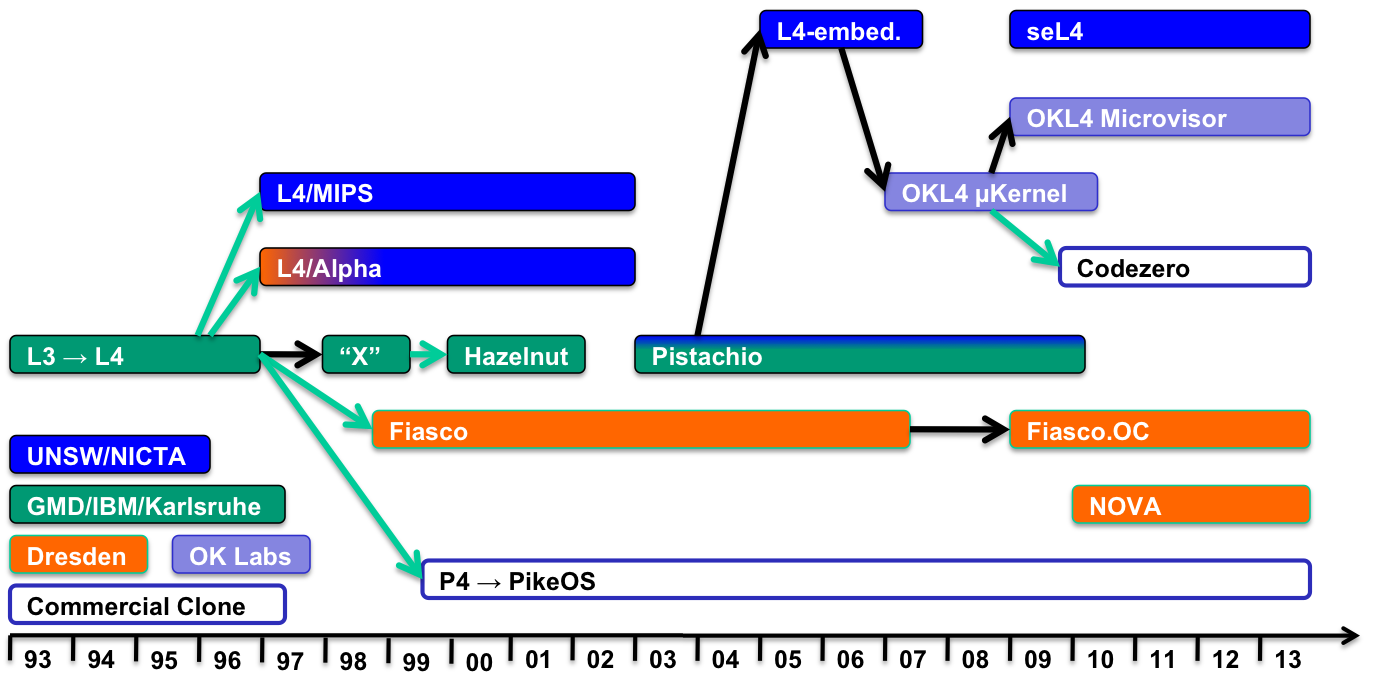
- 歷史
- μ-kernel的基礎概念是由Per Brinch Hansen提出的(Brinch Hansen, Communications of the ACM, 13, 1970)。1980年代在CMU有一個Mach Project,這就是第一代的μ-kernel,而且有很多類似的計畫都在1990左右誕生,但這些第一代的微內核因為效能表現不佳而無法存活下來,而效能不佳的原因有很大的部份就是IPC耗費太多資源。 接著Jochen Liedtke證明了IPC是可以被大幅度改善的,他展示了原來Mach Project低落的效能是因為糟糕的設計與實作,造成大量的cache miss。L4與其他這種類型的系統被稱作第二代的μ-kernel。
L4 microkernel
L4屬於第二代的微內核,通常被用來實作Unix-like的作業系統。
L4與他的前代L3一樣,都是由德國電腦科學家Jochen Liedtke做出來的,目的是為了反應前代不好的效能表現。Jochen Liedtke認為系統的設計應該以高效能為目的出發,如此才能做出實際上可以使用的東西。他最初以Intel i386的組合語言實作出系統後,馬上引起電腦工業圈的熱烈關注。自從L4問世以來,L4已經被發展成獨立於平台之上,並且改善安全性(security)、獨立性(isolation)、以及容錯性(robustness)。
現在已經有很多版本重新實作原來L4的ABI,例如:L4Ka::Pistachio、L4/MIPS、Fiasco。因此現在L4不再指Liedtke最初實作的版本,而是指所有包含L4核心界面的μ-kernel家族。這其中有一個OKL4版本,已經在超過15億的行動裝置上使用(L4 + AMSS)。
作業系統架構
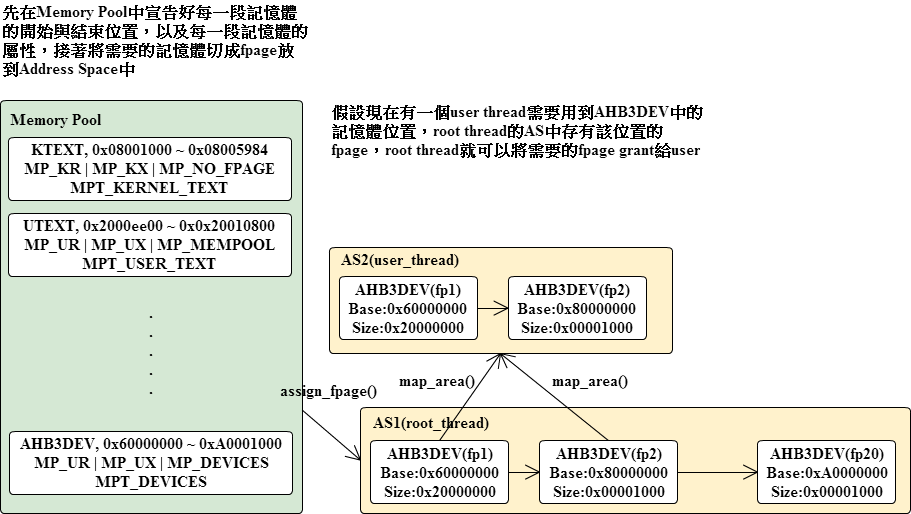
記憶體管理(Memory Management)
與傳統L4用來建置large system的設計理念不同,F9將重點放在小型MCU的功耗上,因此:
- 沒有虛擬記憶體(virtual memory)與分頁(pages)
- RAM很小,但PAS(physical address space)比較大(32-bit),包含:硬體裝置、flash、bit-band區域
- 只有8個MPU(memory protection unit)區域
記憶體管理分為三個部份:
Memory pool 一塊含有特定屬性的PAS區域(hardcoded in memmap table)
Flexible page AS中的一塊區域,與L4不同,這邊是指MPU區域
Address page 由flexible page所組成
提供下列三種管理Address Space的方式:
- MAP - 分享記憶體,memory page被傳送給另一位使用者,且可被兩者使用
- GRANT - memory page會被授權給新的使用者,而且不能在被前一位使用者使用
- UNMAP - 被map到其他使用者的memory page,會從他們的AS中被洗掉
在Cortex-M中,MPU只支援2^n大小的區域,假設我們要建立一個96 bytes的page,我們應該要切成較小的區域,並且建立出一條包含32 byte與64 byte的fpage chain,這邊就是實作複雜的原因。
Memory pool
Memory pool定義出每個記憶體區段的起始位置以及結束位置,並且設定每個區段的屬性(存取權限等等),之後在使用這些記憶體時就要依照每個區段所設定的屬性做出對應的動作。
/* include/memory.h */
typedef struct {
memptr_t start;
memptr_t end;
uint32_t flags;
uint32_t tag;
} mempool_t;
/* Kernel permissions flags */
#define MP_KR 0x0001
#define MP_KW 0x0002
#define MP_KX 0x0004
/* Userspace permissions flags */
#define MP_UR 0x0010
#define MP_UW 0x0020
#define MP_UX 0x0040
/* Fpage type */
#define MP_NO_FPAGE 0x0000 /*! Not mappable */
#define MP_SRAM 0x0100 /*! Fpage in SRAM: granularity 1 << */
#define MP_AHB_RAM 0x0200 /*! Fpage in AHB SRAM: granularity 64 words, bit bang mappings */
#define MP_DEVICES 0x0400 /*! Fpage in AHB/APB0/AHB0: granularity 16 kB */
#define MP_MEMPOOL 0x0800 /*! Entire mempool is mapped */
/* Map memory from mempool always (for example text is mapped always because
* without it thread couldn't run)
* other fpages mapped on request because we limited in MPU resources)
*/
#define MP_MAP_ALWAYS 0x1000
typedef enum {
MPT_KERNEL_TEXT,
MPT_KERNEL_DATA,
MPT_USER_TEXT,
MPT_USER_DATA,
MPT_AVAILABLE,
MPT_DEVICES,
MPT_UNKNOWN = -1
} mempool_tag_t;
#define DECLARE_MEMPOOL(name_, start_, end_, flags_, tag_) \
{ \
.start = (memptr_t) (start_), \
.end = (memptr_t) (end_), \
.flags = flags_, \
.tag = tag_ \
}
#define DECLARE_MEMPOOL_2(name, prefix, flags, tag) \
DECLARE_MEMPOOL(name, &(prefix ## _start), &(prefix ## _end), flags, tag)mempool_t定義出memory
pool的結構,也就是PAS中的一個區域,因此此結構中包含:起始與結束位置、kernel與user的使用權限,還有fpage的creation
rule。DECLARE_MEMPOOL與DECLARE_MEMPOOL_2用來宣告memory
pool,兩者的差異在於定義start與end的位置,一個是直接賦值,一個是透過變數取值
/* kernel/memory.c */
/**
* Memory map of MPU.
* Translated into memdesc array in KIP by memory_init
*/
static mempool_t memmap[] = {
DECLARE_MEMPOOL_2("KTEXT" , kernel_text, MP_KR | MP_KX | MP_NO_FPAGE, MPT_KERNEL_TEXT),
DECLARE_MEMPOOL_2("UTEXT" , user_text, MP_UR | MP_UX | MP_MEMPOOL | MP_MAP_ALWAYS, MPT_USER_TEXT),
DECLARE_MEMPOOL_2("KIP" , kip, MP_KR | MP_KW | MP_UR | MP_SRAM, MPT_KERNEL_DATA),
DECLARE_MEMPOOL("KDATA" , &kip_end, &kernel_data_end,MP_KR | MP_KW | MP_NO_FPAGE, MPT_KERNEL_DATA),
DECLARE_MEMPOOL_2("KBSS" , kernel_bss, MP_KR | MP_KW | MP_NO_FPAGE, MPT_KERNEL_DATA),
DECLARE_MEMPOOL_2("UDATA" , user_data, MP_UR | MP_UW | MP_MEMPOOL | MP_MAP_ALWAYS, MPT_USER_DATA),
DECLARE_MEMPOOL_2("UBSS" , user_bss, MP_UR | MP_UW | MP_MEMPOOL | MP_MAP_ALWAYS, MPT_USER_DATA),
DECLARE_MEMPOOL("MEM0" , &user_bss_end, 0x2001c000, MP_UR | MP_UW | MP_SRAM, MPT_AVAILABLE),
#ifdef CONFIG_BITMAP_BITBAND
DECLARE_MEMPOOL("KBITMAP" , &bitmap_bitband_start, &bitmap_bitband_end,MP_KR | MP_KW | MP_NO_FPAGE, MPT_KERNEL_DATA),
#else
DECLARE_MEMPOOL("KBITMAP" , &bitmap_start, &bitmap_end,MP_KR | MP_KW | MP_NO_FPAGE, MPT_KERNEL_DATA),
#endif
DECLARE_MEMPOOL("MEM1" , &kernel_ahb_end, 0x10010000,MP_UR | MP_UW | MP_AHB_RAM, MPT_AVAILABLE),
DECLARE_MEMPOOL("APB1DEV" , 0x40000000, 0x40007800,MP_UR | MP_UW | MP_DEVICES, MPT_DEVICES),
DECLARE_MEMPOOL("APB2_1DEV", 0x40010000, 0x40013400,MP_UR | MP_UW | MP_DEVICES, MPT_DEVICES),
DECLARE_MEMPOOL("APB2_2DEV", 0x40014000, 0x40014c00,MP_UR | MP_UW | MP_DEVICES, MPT_DEVICES),
DECLARE_MEMPOOL("AHB1_1DEV", 0x40020000, 0x40022400,MP_UR | MP_UW | MP_DEVICES, MPT_DEVICES),
DECLARE_MEMPOOL("AHB1_2DEV", 0x40023c00, 0x40040000,MP_UR | MP_UW | MP_DEVICES, MPT_DEVICES),
DECLARE_MEMPOOL("AHB2DEV" , 0x50000000, 0x50061000,MP_UR | MP_UW | MP_DEVICES, MPT_DEVICES),
DECLARE_MEMPOOL("AHB3DEV" , 0x60000000, 0xA0001000,MP_UR | MP_UW | MP_DEVICES, MPT_DEVICES),
};
// 如果addr落在size當中,則會將addr加上size對齊,不過不須對齊的情況應該直接return addr就好
static memptr_t addr_align(memptr_t addr, size_t size)
{
if (addr & (size - 1))
return (addr & ~(size - 1)) + size;
return (addr & ~(size - 1));
}
void memory_init()
{
int i = 0, j = 0;
uint32_t *shcsr = (uint32_t *) 0xE000ED24;
fpages_init();
ktable_init(&as_table);
mem_desc = (kip_mem_desc_t *) kip_extra;
/* Initialize mempool table in KIP */
for (i = 0; i < sizeof(memmap) / sizeof(mempool_t); ++i) {
switch (memmap[i].tag) {
case MPT_USER_DATA:
case MPT_USER_TEXT:
case MPT_DEVICES:
case MPT_AVAILABLE:
mem_desc[j].base = addr_align((memmap[i].start), CONFIG_SMALLEST_FPAGE_SIZE) | i;
mem_desc[j].size = addr_align((memmap[i].end - memmap[i].start), CONFIG_SMALLEST_FPAGE_SIZE) | memmap[i].tag;
j++;
break;
}
}
// memory_desc_ptr需要存的是從kip到mem_desc的offset
kip.memory_info.s.memory_desc_ptr = ((void *) mem_desc) - ((void *) &kip);
kip.memory_info.s.n = j;
*shcsr |= 1 << 16; /* Enable memfault */
}
INIT_HOOK(memory_init, INIT_LEVEL_KERNEL_EARLY);memory_init先初始化fpages以及as_table,接著將mempool table的填入KIP中。0xE000ED24在ARM
Cortex-M4中是System Handler Control and State
Register(SHCSR),最後enable memfault exception。
Flexible pages(fpage)
在F9中,每一個fpage都是可以直接被mpu使用的分頁,而AS就是由fpage所組成。
/* include/fpage.h */
struct fpage {
struct fpage *as_next;
struct fpage *map_next;
struct fpage *mpu_next;
union {
struct {
uint32_t base;
uint32_t mpid : 6;
uint32_t flags : 6;
uint32_t shift : 16;
uint32_t rwx : 4;
} fpage;
uint32_t raw[2];
};
};
typedef struct fpage fpage_t;一個fpage包含:base address、memory pool id、flags、size、permission,
/* kernel/fpage.c */
static int fp_addr_log2(memptr_t addr)
{
int shift = 0;
while ((addr <<= 1) != 0)
++shift;
return 31 - shift;
}
static fpage_t *create_fpage(memptr_t base, size_t shift, int mpid)
{
fpage_t *fpage = (fpage_t *) ktable_alloc(&fpage_table);
assert(fpage != NULL);
fpage->as_next = NULL;
fpage->map_next = fpage; /* That is first fpage in mapping */
fpage->mpu_next = NULL;
fpage->fpage.mpid = mpid;
fpage->fpage.flags = 0;
fpage->fpage.rwx = MP_USER_PERM(mempool_getbyid(mpid)->flags);
fpage->fpage.base = base;
fpage->fpage.shift = shift;
if (mempool_getbyid(mpid)->flags & MP_MAP_ALWAYS)
fpage->fpage.flags |= FPAGE_ALWAYS;
return fpage;
}create_fpage用來建立並初始化一個新的fpage,首先先在fpage_table中要一塊新的空間,接著依據給予的參數(mpid、size、flags)進行設定。
static void create_fpage_chain(memptr_t base, size_t size, int mpid, fpage_t **pfirst, fpage_t **plast)
{
int shift, sshift, bshift;
fpage_t *fpage = NULL;
while (size) {
/* Select least of log2(base), log2(size). Needed to make regions with correct align */
bshift = fp_addr_log2(base);
sshift = fp_addr_log2(size);
shift = ((1 << bshift) > size) ? sshift : bshift;
if (!*pfirst) {
/* Create first page */
fpage = create_fpage(base, shift, mpid);
*pfirst = fpage;
*plast = fpage;
} else {
/* Build chain */
fpage->as_next = create_fpage(base, shift, mpid);
fpage = fpage->as_next;
*plast = fpage;
}
size -= (1 << shift);
base += (1 << shift);
}
}
/********************** Example *************************
Base 0x60000000 0110 0000 0000 0000 0000 0000 0000 0000
End 0xA0001000 1010 0000 0000 0000 0001 0000 0000 0000
Size 0x40001000 0100 0000 0000 0000 0001 0000 0000 0000
1.
Base 0x60000000 0110 0000 0000 0000 0000 0000 0000 0000
Size 0x40001000 0100 0000 0000 0000 0001 0000 0000 0000
2^Log2(Base) < Size => Create a fpage with 2^Log2(Base)
Base = 0x60000000 + 0x20000000 = 0x80000000
2.
Base 0x80000000 1000 0000 0000 0000 0000 0000 0000 0000
Size 0x20001000 0010 0000 0000 0000 0001 0000 0000 0000
2^Log2(Base) > Size => Create a fpage with 2^Log2(Size)
Base = 0x80000000 + 0x00001000 = 0x80001000
3.
Base 0x80001000 1000 0000 0000 0000 0001 0000 0000 0000
Size 0x20000000 0010 0000 0000 0000 0000 0000 0000 0000
2^Log2(Base) < Size => Create a fpage with 2^Log2(Base)
Base = 0x80001000 + 0x00001000 = 0x80010000
*******************************************************/create_fpage_chain會根據base位置以及大小,建立一條鍊結,如果原來已經有鍊結存在,則會將新產生的fpage鍊接在元有的鍊結上;如果沒有就新建一條鍊結。因為MPU的區域大小必須是2的次方,所以在建立fpage的大小時會先計算出適合的大小,一個一個的將fpage連接起來。
int assign_fpages_ext(int mpid, as_t *as, memptr_t base, size_t size, fpage_t **pfirst, fpage_t **plast)
{
fpage_t **fp;
memptr_t end;
if (size <= 0)
return -1;
/* if mpid is unknown, search using base addr */
if (mpid == -1) {
if ((mpid = mempool_search(base, size)) == -1) {
/* Cannot find appropriate mempool, return error */
return -1;
}
}
end = base + size;
if (as) {
/* find unmapped space */
fp = &as->first;
while (base < end && *fp) {
if (base < FPAGE_BASE(*fp)) {
fpage_t *first = NULL, *last = NULL;
size = (end < FPAGE_BASE(*fp) ? end : FPAGE_BASE(*fp)) - base;
create_fpage_chain(mempool_align(mpid, base),
mempool_align(mpid, size),
mpid, &first, &last);
last->as_next = *fp;
*fp = first;
fp = &last->as_next;
if (!*pfirst)
*pfirst = first;
*plast = last;
base = FPAGE_END(*fp);
} else if (base < FPAGE_END(*fp)) {
if (!*pfirst)
*pfirst = *fp;
*plast = *fp;
base = FPAGE_END(*fp);
}
fp = &(*fp)->as_next;
}
if (base < end) {
fpage_t *first = NULL, *last = NULL;
size = end - base;
create_fpage_chain(mempool_align(mpid, base),
mempool_align(mpid, size),
mpid, &first, &last);
*fp = first;
if (!*pfirst)
*pfirst = first;
*plast = last;
}
} else {
create_fpage_chain(mempool_align(mpid, base),
mempool_align(mpid, size),
mpid, pfirst, plast);
}
return 0;
}
int assign_fpages(as_t *as, memptr_t base, size_t size)
{
fpage_t *first = NULL, *last = NULL;
return assign_fpages_ext(-1, as, base, size, &first, &last);
}最後就是利用assign_fpages將fpage放到AS中
Address space(AS)
/* include/memory.h */
typedef struct {
uint32_t as_spaceid; /*! Space Identifier */
struct fpage *first; /*! head of fpage list */
struct fpage *mpu_first; /*! head of MPU fpage list */
struct fpage *mpu_stack_first; /*! head of MPU stack fpage list */
uint32_t shared; /*! shared user number */
} as_t; /* kernel/memory.c */
void as_map_user(as_t *as)
{
int i;
for (i = 0; i < sizeof(memmap) / sizeof(mempool_t); ++i) {
switch (memmap[i].tag) {
case MPT_USER_DATA:
case MPT_USER_TEXT:
/* Create fpages only for user text and user data */
assign_fpages(as, memmap[i].start, (memmap[i].end - memmap[i].start));
}
}
}替user text以及user data建立fpage,並且映射到as。
int map_area(as_t *src, as_t *dst, memptr_t base, size_t size, map_action_t action, int is_priviliged)
{
memptr_t end = base + size, probe = base;
fpage_t *fp = src->first, *first = NULL, *last = NULL;
int last_invalid = 0;
/* For priviliged thread (ROOT), we use shadowed mapping,
* so first we will check if that fpages exist and then
* create them.
*/
if (is_priviliged) {
assign_fpages_ext(-1, src, base, size, &first, &last);
if (src == dst) {
/* Maps to itself, ignore other actions */
return 0;
}
} else {
if (src == dst) {
/* Maps to itself, ignore other actions */
return 0;
}
while (fp) {
if (!first && addr_in_fpage(base, fp, 0)) {
first = fp;
}
if (!last && addr_in_fpage(end, fp, 1)) {
last = fp;
break;
}
if (first) {
/* Check weather if addresses in fpage list
* are sequental
*/
if (!addr_in_fpage(probe, fp, 1))
return -1;
probe += (1 << fp->fpage.shift);
}
fp = fp->as_next;
}
}
if (!last || !first) {
/* Not in address space or error */
return -1;
}
if (first == last)
last_invalid = 1;
/* That is a problem because we should split
* fpages into two (and split all mappings too)
*/
first = split_fpage(src, first, base, 1);
/* If first and last were same pages, after first split,
* last fpage will be invalidated, so we search it again
*/
if (last_invalid) {
fp = first;
while (fp) {
if (addr_in_fpage(end, fp, 1)) {
last = fp;
break;
}
fp = fp->as_next;
}
}
last = split_fpage(src, last, end, 0);
if (!last || !first) {
/* Splitting not supported for mapped pages */
/* UNIMPLIMENTED */
return -1;
}
/* Map chain of fpages */
fp = first;
while (fp != last) {
map_fpage(src, dst, fp, action);
fp = fp->as_next;
}
map_fpage(src, dst, fp, action);
return 0;
}map_area將指定的base位置以及大小,從來源的AS中找出符合的fpage映射到目的AS
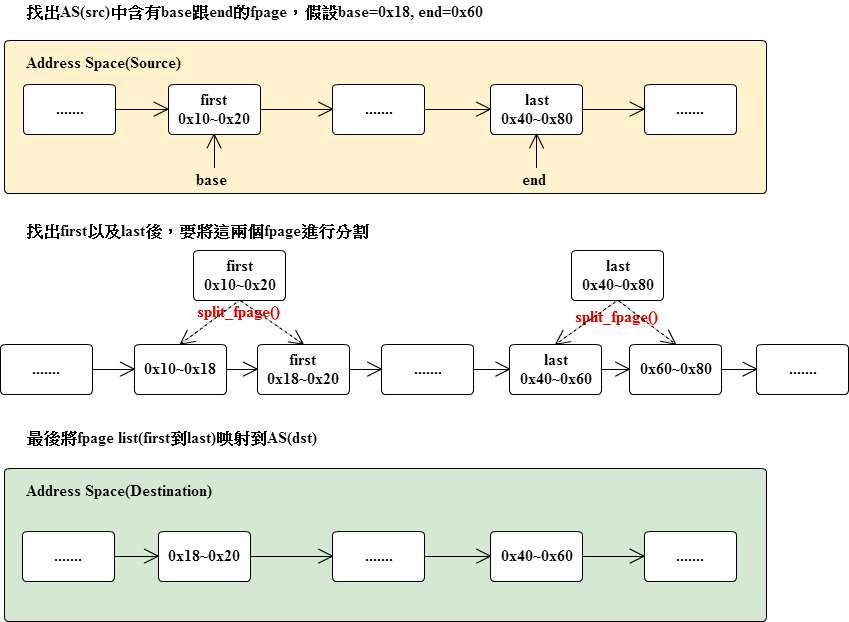
/* kernel/memory.c */
void as_setup_mpu(as_t *as, memptr_t sp, memptr_t pc, memptr_t stack_base, size_t stack_size)
{
fpage_t *mpu[8] = {NULL};
fpage_t *fp;
int mpu_first_i;
int i, j;
fpage_t *mpu_stack_first = NULL;
memptr_t start = stack_base;
memptr_t end = stack_base + stack_size;
/* 找到 stack 是在哪些 fpage 中,並且把這些 fpage 放到 mpu 陣列中 */
fp = as->first;
i = 0;
while (i < 8 && fp != NULL && start < end) {
if (addr_in_fpage(start, fp, 0)) {
if (!mpu_stack_first)
mpu_stack_first = fp;
mpu[i++] = fp;
start = FPAGE_END(fp);
}
fp = fp->as_next;
}
as->mpu_stack_first = mpu_stack_first;
mpu_first_i = i;
/*
* 如果還沒有設定過mpu,則掃過整個 fpage 序列,並將他們分成下面三類,最後依照順序串成一列放到 as->mpu_first
* mpu_fp[0] are pc
* mpu_fp[1] are always-mapped fpages
* mpu_fp[2] are others
*/
fp = as->mpu_first;
if (fp == NULL) {
fpage_t *mpu_first[3] = {NULL};
fpage_t *mpu_fp[3] = {NULL};
fp = as->first;
while (fp != NULL) {
int priv = 2;
if (addr_in_fpage(pc, fp, 0)) {
priv = 0;
} else if (fp->fpage.flags & FPAGE_ALWAYS) {
priv = 1;
}
if (mpu_first[priv] == NULL) {
mpu_first[priv] = fp;
mpu_fp[priv] = fp;
} else {
mpu_fp[priv]->mpu_next = fp;
mpu_fp[priv] = fp;
}
fp = fp->as_next;
}
if (mpu_first[1]) {
mpu_fp[1]->mpu_next = mpu_first[2];
} else {
mpu_first[1] = mpu_first[2];
}
if (mpu_first[0]) {
mpu_fp[0]->mpu_next = mpu_first[1];
} else {
mpu_first[0] = mpu_first[1];
}
as->mpu_first = mpu_first[0];
}
/* 將剩下的 fpage 放到 mpu 中,因為 stack 的 fpage 已經放過了,所以要忽略 */
for (fp = as->mpu_first; i < 8 && fp != NULL; fp = fp->mpu_next) {
for (j = 0; j < mpu_first_i; j++) {
if (fp == mpu[j]) {
break;
}
}
if (j == mpu_first_i) {
mpu[i++] = fp;
}
}
/* 設定 mpu_first 為第一個非 stack 的 fpage */
as->mpu_first = mpu[mpu_first_i];
/* Setup MPU stack regions */
for (j = 0; j < mpu_first_i; ++j) {
mpu_setup_region(j, mpu[j]);
if (j < mpu_first_i - 1)
mpu[j]->mpu_next = mpu[j + 1];
else
mpu[j]->mpu_next = NULL;
}
/* Setup MPU fifo regions */
for (; j < i; ++j) {
mpu_setup_region(j, mpu[j]);
if (j < i - 1)
mpu[j]->mpu_next = mpu[j + 1];
}
/* Clean unused MPU regions */
for (; j < 8; ++j) {
mpu_setup_region(j, NULL);
}
}這個函式會在thread_switch()中用到,使用概念可以參考後面的MPU段落,有詳細介紹MPU在context
switch上的應用。
Interrupt Request(IRQ)
Context Switch
在大部分搶佔式的 RTOS(ARM Cortex) 中,都會使用 PendSV
實作上下文切換。PendSV 是 ARM Cortex 中一個特別的 exception
,可以從軟體驅動產生中斷。要觸發 PendSV 的方法很簡單,透過設定
ICSR(Interrupt Control and State Register)
暫存器中的PENDSVSET為1,就可以將 PendSV
的狀態切換至pending。
/* include/platform/irq.h */
#define request_schedule() \
do { *SCB_ICSR |= SCB_ICSR_PENDSVSET; } while (0)在 F9-kernel 中,會使用這個巨集觸發 PendSV,接著透過 PendSV Handler 處理上下文切換。
/* include/platform/irq.h */
// 這邊為了簡化觀察,省略了 FPU 的部份
#define irq_save(ctx) \
__asm__ __volatile__ ("cpsid i"); \
__asm__ __volatile__ ("mov r0, %0" : : "r" ((ctx)->regs) : "r0"); \
__asm__ __volatile__ ("stm r0, {r4-r11}"); \
__asm__ __volatile__ ("and r4, lr, 0xf":::"r4"); \
__asm__ __volatile__ ("teq r4, #0x9"); \
__asm__ __volatile__ ("ite eq"); \
__asm__ __volatile__ ("mrseq r0, msp"::: "r0"); \
__asm__ __volatile__ ("mrsne r0, psp"::: "r0"); \
__asm__ __volatile__ ("mov %0, r0" : "=r" ((ctx)->sp)); \
__asm__ __volatile__ ("mov %0, lr" : "=r" ((ctx)->ret));
#define irq_restore(ctx) \
__asm__ __volatile__ ("mov lr, %0" : : "r" ((ctx)->ret)); \
__asm__ __volatile__ ("mov r0, %0" : : "r" ((ctx)->sp)); \
__asm__ __volatile__ ("mov r2, %0" : : "r" ((ctx)->ctl)); \
__asm__ __volatile__ ("and r4, lr, 0xf":::"r4"); \
__asm__ __volatile__ ("teq r4, #0x9"); \
__asm__ __volatile__ ("ite eq"); \
__asm__ __volatile__ ("msreq msp, r0"); \
__asm__ __volatile__ ("msrne psp, r0"); \
__asm__ __volatile__ ("mov r0, %0" : : "r" ((ctx)->regs)); \
__asm__ __volatile__ ("ldm r0, {r4-r11}"); \
__asm__ __volatile__ ("msr control, r2"); \
__asm__ __volatile__ ("cpsie i");irq_save()跟irq_restore()分別用來儲存與取出
context,在存取 context
的過程中是不能被中斷的,所以前後要分別加上cpsid i以及cpsie i。需要保存的資料包括:r4-r11、link register、stack pointer。
/* platform/irq.c */
// 這邊我直接將巨集展開,方便觀察
extern volatile tcb_t *current;
void pendsv_handler(void) __NAKED;
void pendsv_handler(void)
{
__asm__ __volatile__ ("push {lr}");
register tcb_t *sel;
sel = schedule_select();
if (sel != current) {
__asm__ __volatile__ ("pop {lr}");
irq_save(&(current)->ctx);
thread_switch((sel));
irq_restore(&(current)->ctx);
__asm__ __volatile__ ("bx lr");
}
__asm__ __volatile__ ("pop {lr}");
__asm__ __volatile__ ("bx lr");
}
/* kernel/thread.c */
void thread_switch(tcb_t *thr)
{
assert(thr != NULL);
assert(thread_isrunnable(thr));
current = thr;
current_utcb = thr->utcb;
if (current->as)
as_setup_mpu(current->as, current->ctx.sp, ((uint32_t*)current->ctx.sp)[REG_PC], current->stack_base, current->stack_size);
}實作 pendsv_handler
時是宣告成[]_NAKED的,所以必須自己處理函式呼叫的prologue、epilogue,因為沒有對 stack 進行處理,在使用 local 變數的時候加上register修飾,強制將變數存放在暫存器中(編譯器判斷有空閒的暫存器的話),接著呼叫schedule_select()取得排程的下一個任務進行切換。切換的方法是先將目前任務的 ctx(包含lr) 儲存,接著將current切換成下一個任務,最後取出新任務的 ctx,這時 lr 會是新任務的返回地址,因此就可以使用bx
lr``恢復任務。但如果排程器選出的任務與當前任務是一樣的,代表不需要切換,也就不需要進行
ctx 的儲存,可以直接在將 lr 從堆疊中取出,並且返回。
下面列出irq_save()、irq_restore()以及context_switch()的流程:
irq_save:
- 關閉 irq
- 取得context中regs的位置
- 將 r4 - r11 存到 regs 中
- 利用 lr & 0xF == 0x9 判斷是使用 main stack 還是 process stack
- 將 stack pointer 存到 context 中的sp
- 將 lr 存到 context 中的 ret
irq_restore:
- 取回 sp、lr、ctl
- 利用 lr & 0xF == 0x9 判斷是使用 main stack 還是 process stack
- 將stack pointer寫入 psp或是msp
- 取回 r4 - r11
- 設定 control
- 開啟irq
context switch過程:
- 進入pendsv_handler時將lr堆到stack中,這時候的lr是進入pendsv前的下一步指令
- 在schedule_in_irq中取得排程後要執行的下一個task,進行context switch
- 先從stack中將剛剛push進去的lr取出,將目前task的context儲存起來
- 切換thread,current被設定成新的task
- 取回新task的context,bx到新task的lr(新task在第一步驟時存的lr),完成context switch
IRQ Handler
F9-kernel 提供一個用來定義 IRQ Handler 的巨集
/* include/platform/irq.h */
// 為了觀察方便,將內部的巨集展開
#define IRQ_HANDLER(name, sub) \
void name(void) __NAKED; \
void name(void) \
{ \
__asm__ __volatile__ ("push {lr}"); \
sub(); \
do { *SCB_ICSR |= SCB_ICSR_PENDSVSET; } while (0) \
__asm__ __volatile__ ("pop {lr}"); \
__asm__ __volatile__ ("bx lr"); \
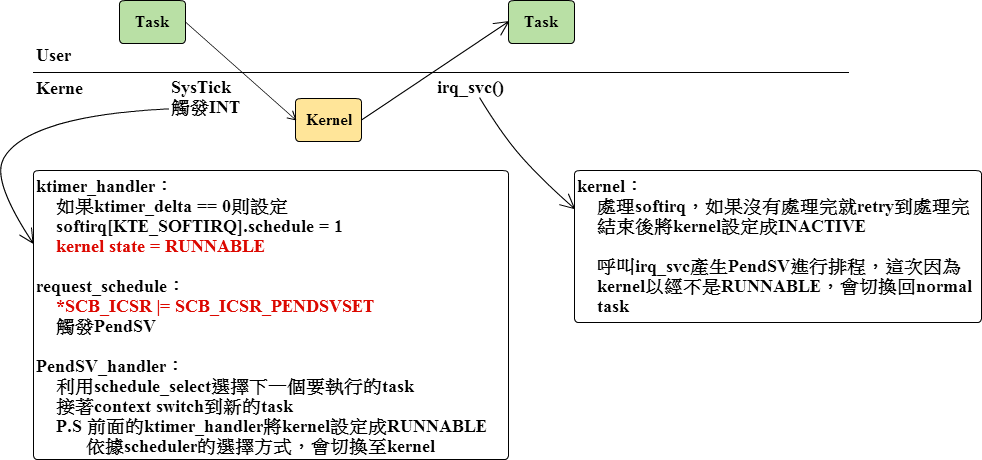
}使用這個巨集定義的 IRQ Handler,在處理完自己本身的服務後,會拉起 PendSV 進行上下文切換。目前 F9 當中有下列這些 IRQ Handler 都是使用這個巨集定義的:
$ grep IRQ_HANDLER kernel/* platform/* platform/stm32f4/*
kernel/ktimer.c:IRQ_HANDLER(ktimer_handler, __ktimer_handler);
kernel/syscall.c:IRQ_HANDLER(svc_handler, __svc_handler);
platform/debug_uart.c:IRQ_HANDLER(BOARD_UART_HANDLER, __uart_irq_handler);
platform/stm32f4/mpu.c:IRQ_HANDLER(memmanage_handler, __memmanage_handler);下圖是 SysTick 中斷的處理過程:
硬體驅動原理
Flash Patch and Breakpoint Unit (FPB), ARMv7-M Debug Architecture
- 六個程式中斷點和兩個資料存取中斷點
- 把程式指令和資料以補丁方式從code space 放到system space
FPB unit 包含了六個指令比較單位,兩個資料比較單位。指令比較單位可以把code重新映射到system space,也可以做為硬體中斷點,負責將中斷指令傳送給processor;而資料比較單位負責配對從code space讀取的資料,並將它們重新映射到system space。
FPB register的起始位置在cortex-M 中為0xe0002000
/* FPB Flash Patch and Breakpoint unit Registers */
#define FPB_MAX_COMP 6
#define FPB_BASE (uint32_t) (0xE0002000)
#define FPB_CTRL (volatile uint32_t *) (FPB_BASE)
#define FPB_REMAP (volatile uint32_t *) (FPB_BASE + 0x04)
#define FPB_COMP (volatile uint32_t *) (FPB_BASE + 0x08)- BKPT
BKPT是ARM的指令,它會讓處理器進入Debug State,可以讓除錯工具在特定的address檢查系統狀態。其用法為
其中處理器會忽略imm,imm可以讓除錯者傳送一些訊息。 BKPT也可以放在條件指令中來檢查是否進入異常狀態。
- Debug
Arm提供兩個除錯模式:
* Halt mode
- 處理器將程式完全停下,然後可以進行single step,所有interrupt都可被pended,將在single step中處理,也可masked interrupt。
* Debug monitor mode
- 處理器用exception_handler來呼叫debug任務,同時依然讓更高權限的exception執行,同樣支援single step。在 single step 時候,每一個step之後都會進入 exception_handler,F9也用這方法來進行 prehandler 和 posthandler。
此外,ARM也提供debug registers
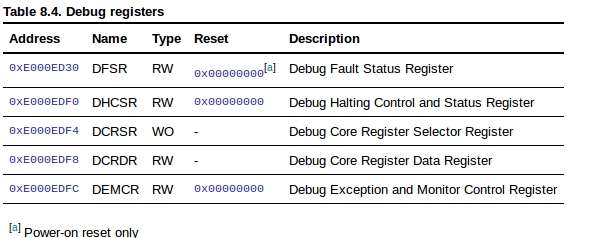
F9使用的是 Debug monitor mode。
//platform/breakpoint-hard.c
void hard_breakpoint_pool_init(void)
{
...
/* Enable DWT watchpoint & DebugMon exception */
*DCB_DEMCR |= DCB_DEMCR_TRCENA | DCB_DEMCR_MON_EN;
...
}MPU (Memory Protection Unit)
- Overview
在multitasking的系統中,必須確保不同task的操作不會互相干擾,而避免系統資源或是其他任務的資料被非法存取的機制就叫做保護(protection)。控制存取系統資源的方法有兩種:無硬體保護與有硬體保護,無硬體保護的系統就單純依靠軟體保護系統資源;有硬體保護的則是會由硬體與軟體一起進行保護。至於實際上的控制系統要使用哪種方法,取決於處理器的性能以及控制系統的需求。
在無保護的系統中,沒有專門處理週邊設備以及記憶體的硬體,在這類的系統中,為了避免不同的task有互相干擾的情況,必須有協調的機制,但如果其中有任務沒有遵守存取限制,則這個機制就可能失敗。下面是一個失敗的例子:當讀寫一個通訊用的序列阜(serial port)暫存器時,如果有一個任務正在使用序列阜,但他沒辦法阻止其他任務也使用相同的序列阜。所以,要順利的使用序列阜,就必須設計一個存取該序列阜的系統呼叫。但這些未經授權的任務在使用系統呼叫時,很容易就會破壞序列阜的通訊。
反過來說,在有保護的系統中,會有專門檢查並限制存取系統資源的硬體,它可以保證資源的所有權,任務必須遵守一組由操作環境定義的規則,而這規則會由硬體來維護,從硬體等級上授予監看和控制資源的特殊權限。受保護的系統可以防止一個任務使用到其他任務的資源,硬體保護會比使用軟體協調的辦法有更好的保護。
ARM的很多處理器都配有主動保護系統資源的硬體:memory protection unit(MPU)以及memory management unit(MMU)兩種,帶有MPU的處理器可以對一些由軟體定義的區域進行硬體保護;帶有MMU的處理器則是除了提供硬體保護外,還加上了虛擬記憶體(virtual memory)的功能。
在受保護的系統中,主要有兩種資源要監看:記憶體與週邊設備,因為ARM的週邊設備通常會被映射到記憶體中,因此MPU就可以用同樣的方法保護這兩種資源。
ARM Cortex-M4 Optional Memory Protection Unit
MPU會將memory map切成幾塊區域,並定義每一個區域(region)的位置、大小、存取權限還有記憶體屬性(attributes)
- 每一個區域可以有獨立的屬性設定
- 區域可以overlapping
- 可以export記憶體屬性給系統
記憶體屬性會影響區域的記憶體存取,Cortex-M4定義了:
八個獨立的記憶體區域,0-7
一個背景區域(background region)
當overlap發生時,存取權限會以編號較高的區域屬性為準。例如區域7與任何其他的區域發生重疊時,都會以區域7的屬性為主 重疊的區域在賦予存取權限時可以有比較大的彈性,例如有一個小型的嵌入式系統,總共有256KB的記憶體,而起始位置在0x00000000,其中有一塊是privileged的系統區域32KB,不能被使用者存取,並且從0x00000000開始放起,剩下的記憶體則是給使用者。這個系統使用兩個區域:256KB的user區域跟32KB的privileged區域,因為privileged區域的優先度比較大,所以privileged區域使用編號1,user區域使用編號0。
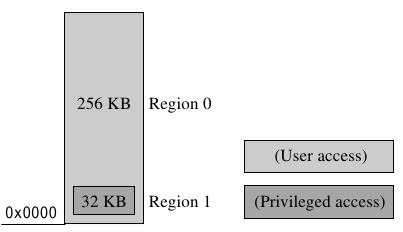
背景區域與預設的memory map有相同的屬性,但是只能被privileged的軟體存取 重疊區域的另一個用處在背景區域-用來替一大塊記憶體空間分配相同屬性的低優先度區域,其他較高優先度的區域就能改變背景區域中的某一塊屬性。背景區域可以用來保護一些睡眠狀態的記憶體,使其不會被非法存取,而此時由另一個處於活躍狀態的記憶體就能被使用。
例如有一個嵌入式系統定義了一個較大的privileged區域,接著讓一些較小的unprivileged區域與這個privileged區域的部份重疊,這個較小區域可以在背景區域的不同位置,代表不同的用戶空間(user space),當系統將這個較小的區域從一個位置移到另一個位置時,之前被覆蓋的空間就會在由背景區域進行保護。這個使用者區域(user region)就像一個window,允許存取背景區域的不同部份,但只有用戶等級(user-level)的屬性。
下圖是一個簡單的3-task保護架構,區域3定義了active task的保護屬性,而背景區域0則負責保護其他睡眠狀態的任務資源。
指令存取(instruction access)與資料存取(data access)是使用相同的區域設定
當程式要存取受到MPU保護的區域時,會產生
MemManage fault(fault exception)。在作業系統的環境中,kernel可以在程式執行時動態更新MPU區域。通常一個嵌入式OS會使用MPU作為memory protection
Implementation
mpu的實作是依賴於硬體的,所以程式碼會放在platform底下
/* include/platform/mpu.h */
#define MPU_BASE_ADDR 0xE000ED9C
#define MPU_ATTR_ADDR 0xE000EDA0
#define MPU_CTRL_ADDR 0xE000ED94
#define MPU_RNR_ADDR 0xE000ED98
#define MPU_REGION_MASK 0xFFFFFFE0這邊先定義好mpu暫存器的位置,這些位置可以從arm的手冊中找到。至於MPU_REGION_MASK是用來取得區域用的遮罩值。
- MPU_BASE(MPU
Region Base Address Register)

- 定義由MPU_RNR指定的MPU區域的base位置,並且更新MPU_RNR中的值,N值是在MPU_RASR中設定的size大小。
- ADDR - 區域的base位置
- VALID
- 0 - MPU_RNR不會改變,處理器會更新由MPU_RNR指定的MPU區域的base位置
- 1 - 將MPU_RNR更新成REGION,更新由MPU_RNR指定的MPU區域的base位置
- 也就是說,設定0的話會更新原來的MPU_RNR區域的base,1的話就是先切換MPU_RNR區域在更新base
- REGION - 區域的index
- MPU_ATTR(MPU
Region Attribute and Size Register)
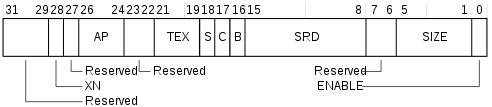
- 定義由MPU_RNR指定的MPU區域的屬性還有大小,並且enable區域與子區域
- XN
- 0 - enable instruction fetch
- 1 - disable instruction fetch
- AP - 存取權限
- TEX, C, B - 記憶體存取屬性
- S - shareable
- SRD
- 0 - 對應子區域enable
- 1 - 對應子區域disable
- 區域在大小在128byte以下不能使用子區域
- SIZE - MPU區域的大小
- ENABLE - 區域enable
- MPU_CTRL(MPU
Control Register)
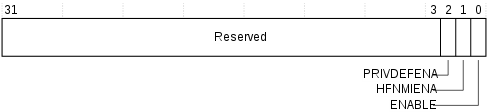
- PRIVDEFENA
- 0 - disable預設的memory map,如果有存取到沒有被enable的區域,會造成錯誤
- 1 - enable預設的memory map,background區域給priviledged軟體使用
- HFNMIENA - 在hard fault、NMI、FAULTMASK handler時要不要啟動MPU
- 0 - disable
- 1 - enable
- ENABLE
- 0 - disable mpu
- 1 - enable mpu
- PRIVDEFENA
/* platform/stm32f4/mpu.c */
void mpu_setup_region(int n, fpage_t *fp)
{
static uint32_t *mpu_base = (uint32_t *) MPU_BASE_ADDR;
static uint32_t *mpu_attr = (uint32_t *) MPU_ATTR_ADDR;
if (fp) {
*mpu_base = (FPAGE_BASE(fp) & MPU_REGION_MASK) | 0x10 | (n & 0xF);
*mpu_attr = ((mempool_getbyid(fp->fpage.mpid)->flags & MP_UX) ?
0 :
(1 << 28)) | /* XN bit */
(0x3 << 24) /* Full access */ |
((fp->fpage.shift - 1) << 1) /* Region */ |
1 /* Enable */;
} else {
/* Clean MPU region */
*mpu_base = 0x10 | (n & 0xF);
*mpu_attr = 0;
}
}*mpu_base = (FPAGE_BASE(fp) & MPU_REGION_MASK) | 0x10 | (n & 0xF),先取得fpage base再遮罩下去取得前27位,接著設定VALID跟REGION- MPU_ATTR設定:
- MP_UX(userspace execute)
- 權限(all)
- 區域大小
- enable
/* platform/stm32f4/mpu.c */
void mpu_enable(mpu_state_t i)
{
static uint32_t *mpu_ctrl = (uint32_t*) MPU_CTRL_ADDR;
*mpu_ctrl = i | MPU_PRIVDEFENA;
}依據參數設定MPU_CTRL狀態,並且開啟PRIVDEFENA
/* platform/stm32f4/mpu.c */
int addr_in_mpu(uint32_t addr)
{
static uint32_t *mpu_rnr = (uint32_t *) MPU_RNR_ADDR;
static uint32_t *mpu_base = (uint32_t *) MPU_BASE_ADDR;
static uint32_t *mpu_attr = (uint32_t *) MPU_ATTR_ADDR;
int i;
for (i = 0; i < 8; ++i) {
*mpu_rnr = i;
if (*mpu_attr & 0x1) {
uint32_t base = *mpu_base & MPU_REGION_MASK;
uint32_t size = 1 << (((*mpu_attr >> 1) & 0x1F) + 1);
if (addr >= base && addr < base + size)
return 1;
}
}
return 0;
}掃過全部的mpu區域,並檢查給予的地址是不是在enable的區域內。
當存取到違反MPU權限設定的區域時,會產生MemManage fault,MemManage
Fault Status Register(MMFSR)位在0xE000ED28,結構如下:
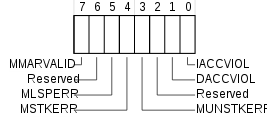
- MMARVALID
- 0 - MMAR中的位置是無效的
- 1 - MMAR中存了有效的fault address
- MLSPERR
- 0 - 在浮點數的lazy state preservation沒有發生MemManage fault
- 1 - 在浮點數的lazy state preservation發生MemManage fault
- MSTKERR
- 0 - 沒有堆疊錯誤
- 1 - 在堆疊exception entry時造成了非法存取
- MUNSTKERR
- 0 - 沒有unstacking錯誤
- 1 - 在unstacking exception return時造成了非法存取
- DACCVIOL
- 0 - 沒有data的存取錯誤
- 1 - processor試圖讀取或儲存一個禁止該操作的位置
- IACCVIOL
- 0 - 沒有instruction的存取錯誤
- 1 - processor試圖在一個禁止instruction fetch的位置進行該操作
/* include/platform/mpu.h */
#define MPU_FAULT_STATUS_ADDR 0xE000ED28
#define MPU_FAULT_ADDRESS_ADDR 0xE000ED34
#define MPU_MEM_FAULT 0x80
#define MPU_MSTKERR 0x10
#define MPU_MUSTKERR 0x08
#define MPU_DACCVIOL 0x02
#define MPU_IACCVIOL 0x01
/* platform/stm32f4/mpu.c */
void __memmanage_handler(void)
{
uint32_t mmsr = *((uint32_t *) MPU_FAULT_STATUS_ADDR);
uint32_t mmar = *((uint32_t *) MPU_FAULT_ADDRESS_ADDR);
tcb_t *current = thread_current();
/* stack errors */
if (mmsr & MPU_MSTKERR) {
panic("Corrupted Stack, current = %t, psp = %p\n", current->t_globalid, PSP());
}
if (mmsr & MPU_MEM_FAULT) {
if (mpu_select_lru(current->as, mmar) == 0)
goto ok;
}
/* unstacking errors */
if (mmsr & MPU_MUSTKERR) {
/* Processor is not writing mmar, so we do it manually */
if (mpu_select_lru(current->as, (uint32_t)PSP() + 31) == 0) {
goto ok;
}
}
if (mmsr & MPU_IACCVIOL) {
uint32_t pc = PSP()[REG_PC];
if (mpu_select_lru(current->as, pc) == 0)
goto ok;
if (mpu_select_lru(current->as, pc + 2) == 0)
goto ok;
}
mpu_dump();
panic("Memory fault mmsr:%p, mmar:%p,\n current:%t, psp:%p, pc:%p\n", mmsr, mmar, current->t_globalid, PSP(), PSP()[REG_PC]);
ok:
/* Clean status register */
*((uint32_t *) MPU_FAULT_STATUS_ADDR) = mmsr;
return;
}
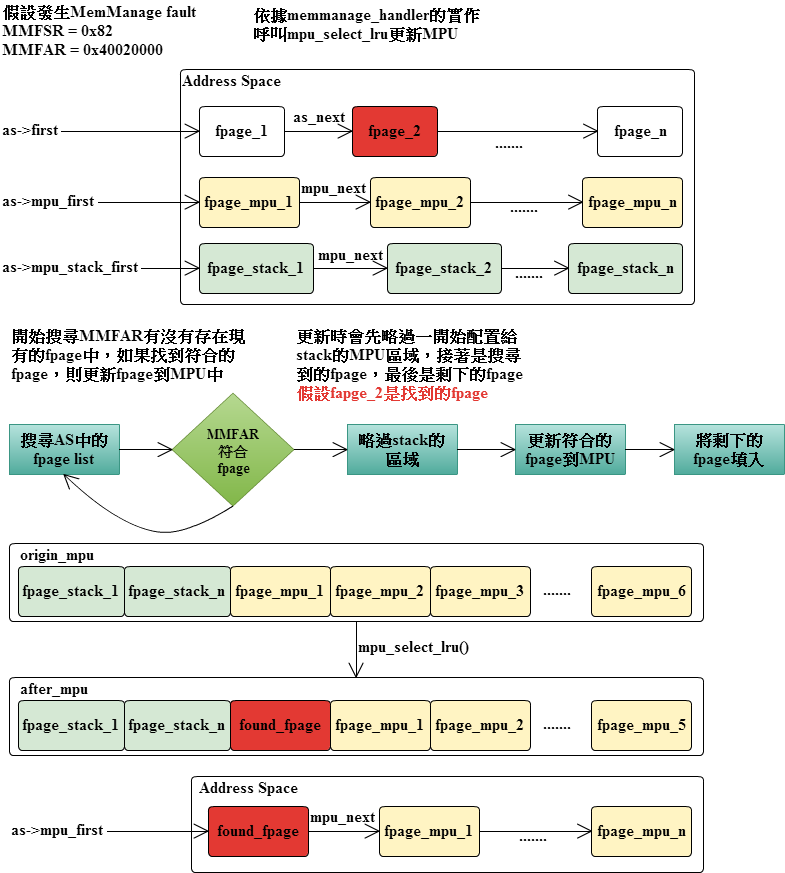
int mpu_select_lru(as_t *as, uint32_t addr)
{
fpage_t *fp = NULL;
int i;
/* Kernel fault? */
if (as == NULL)
return 1;
if (addr_in_mpu(addr))
return 1;
fp = as->first;
while (fp) {
if (addr_in_fpage(addr, fp, 0)) {
fpage_t *sfp = as->mpu_stack_first;
fp->mpu_next = as->mpu_first;
as->mpu_first = fp;
/* Get first avalible MPU index */
i = 0;
while (sfp != NULL) {
++i;
sfp = sfp->mpu_next;
}
/* Update MPU */
mpu_setup_region(i++, fp);
while (i < 8 && fp->mpu_next != NULL) {
mpu_setup_region(i++, fp->mpu_next);
fp = fp->mpu_next;
}
return 0;
}
fp = fp->as_next;
}
return 1;
}mpu_select_lru會找尋目標位址有沒有存在當前的AS中,如果有的話就更新fpage至MPU,更新的方法是先略過前面留給stack的MPU,接著更新目前的fpage,最後接著將之前的fpage依據順序補上。範例如下:
IPC
F9的IPC 性質為同步傳送,舉個同步和非同步的例子:
- 同步 - 當A 要傳送資料給B 時候,會先檢查B 是否已經準備好,如果是的話就直接傳送,不是的話就等待對方。傳送過程中不會經過其他buffer,而是直接傳給B。
- 非同步 - 當A要傳送資料給B 時候,會把資料丟進系統IPC準備好的queue/buffer中; 當B 要接收資料的時候,會從queue/buffer中尋找。過程中需要係統IPC的buffer/queue做為中轉。
IPC register有兩種- message register & buffer register
- MRs有16個
- BR只有8個
Message Register
共有 16 個,其中 0 ~ 7 是 R4 ~ R11,其他的為虛擬Registers是 UTCB中的 MR[0~8]。
//user/include/l4/platform/vregs.h
register L4_Word32_t __L4_MR0 asm ("r4");
register L4_Word32_t __L4_MR1 asm ("r5");
register L4_Word32_t __L4_MR2 asm ("r6");
register L4_Word32_t __L4_MR3 asm ("r7");
register L4_Word32_t __L4_MR4 asm ("r8");
register L4_Word32_t __L4_MR5 asm ("r9");
register L4_Word32_t __L4_MR6 asm ("r10");
register L4_Word32_t __L4_MR7 asm ("r11");
//include/ipc.h
static uint32_t ipc_read_mr(tcb_t *from, int i)
{
// 可以發現 8以下的mr屬於ctx裡的regs
if (i >= 8)
return from->utcb->mr[i - 8];
return from->ctx.regs[i];
}每個MR的值只能被使用一次,一次之後讀取的話會出現undefined結果。
MR 內容可包含
- Untyped word
- Typed item
- MapItem
- GrantItem
- CtrlXferItem (目前未完成)
- StringItem (目前未完成)
一次利用MR傳送的Message可以分為三塊區域:
Message Tag 位置固定在MR[0]。
Untyped Word 位置在MR[1~u],u表示Untyped word的數量。
Typed Word 位置在MR[u+1~u+t],t表示Typed word的數量。
Message Tag的作用是描述本次message的内容。 
* u : untyped words的數量
* t : words裡面有typed item的數量
* label : 使用者自定 opcode
* 0 : 保留
* p : 擴展性此外,Message Tag也是接收内容的描述。 
* u : 收到的Untyped words數量
* t : 收到的Typed items數量
* E : 是否有發生錯誤,從UTCB中查看ErrorCode
* X : 是不是從其他CPU送來的message
* r : message是否有被重新導向
* p : 發送者使用propagation,可以從UTCB中找出真正的發送者 //include/l4/ipc.h
typedef union {
struct {
/* Number of words */
uint32_t n_untyped : 6;
uint32_t n_typed : 6;
uint32_t prop : 1;
uint32_t reserved : 3; /* Type of operation */
uint16_t label;
} s;
uint32_t raw;
} ipc_msg_tag_t;MapItem
Map的動作是透過將要map的fpage組成部分message傳送給Mappee。
Fpage細節由兩個words來組成: 
* r w x : 權限
* snd base : 在L4的文件中,snd base在snd fpage大於/小於接收者能接收的窗口中扮演不同的角色。而在F9的程式碼看起来,snd base是要map的目標位置,而snd fpage是size。GrantItem
Fpage細節也是如同MapItem的兩個words,但其中100C部分由 101C 取代。
CtrlXferItem
從L4 繼承而來,但是在F9未找到相關的程式碼,應該是未完成。
StringItem
在接收端部分,string item用來指定接收到string的buffer register。
目前在F9中是未完成的。
StringItem又可以分為連續和不連續的string:
- Simple String
連續性的bytes。由两個words組成: 
* string ptr :要發送的字串起始位置或者是接收到字串的buffer起始位置。字串和buffer需要完全符合使用者空間可用位置。
* string length :要發送的string長度或者是接收的buffer長度。
* hh :Cache設定。 00為處理器預設cache。- Compound String
一個不連續/鄰近的字串,由落在使用者空間中多個連續性的子字串組成,子字串之間不可以重疊。

* 0hhC在第一個string descriptor word才需要,後面會被忽略。
* j :接下來連續的str-ptr word的數量。
* c :如果是0,則這compound string descriptor word只有j 個word的string之後就結束。如果是1 ,j個word以後會有新的string descriptor word。- String Examples
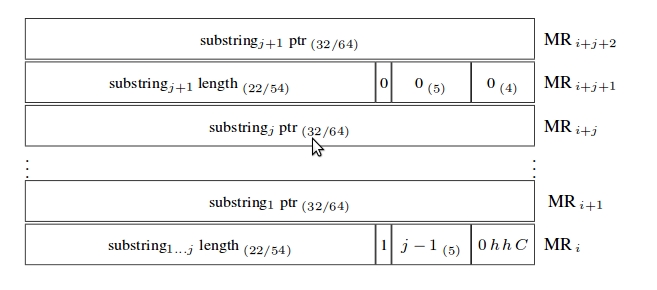
Buffer Register
BR是StringItem和control transfer Item指定Buffer的目的地。
F9中未發现實作。
IPC 過程
若目標thread沒有在等待接收,則caller thread會進入T_SEND_ BLOCKED狀態。
等待接收的目標可以設定成兩種:
- Closed receive:特定thread
- Open wait:任何thread
從pingpong開始trace整個IPC流程
//user/apps/pingpong/main.c
void __USER_TEXT pong_thread(void)
{
...
while(1) {
msgtag = L4_Receive(threads[PING_THREAD]);
L4_MsgStore(msgtag, &msg);
}
}一開始pong會從ping中接收到message tag.
//user/include/l4/ipc.h
L4_INLINE L4_MsgTag_t L4_Receive(L4_ThreadId_t from)
{
/* call L4_Receive_Timeout with no timeout */
return L4_Receive_Timeout(from, L4_Never);
}
L4_INLINE L4_MsgTag_t L4_Receive_Timeout(L4_ThreadId_t from, L4_Time_t RcvTimeout)
{
L4_ThreadId_t dummy;
/*
Call L4_Ipc, the reason that using another function call is
ipc required syscall, and it's different with different hw, so
using another function call to separate the hw-dependent and
not-hw-dependent codes.
*/
return L4_Ipc(L4_nilthread, from, (L4_Word_t) RcvTimeout.raw, &dummy);
}
// user/lib/l4/platform/syscalls.c
L4_MsgTag_t L4_Ipc(L4_ThreadId_t to, L4_ThreadId_t FromSpecifier, L4_Word_t Timeouts, L4_ThreadId_t *from)
{
L4_MsgTag_t result;
L4_ThreadId_t from_ret;
__asm__ __volatile__(
"svc %[syscall_num]\n"
"str r0, %[from]\n"
: [from] "=m"(from_ret)
: [syscall_num] "i"(SYS_IPC));
result.raw = __L4_MR0;
if (from != NULL)
*from = from_ret;
return result;
}所以從pong的接收呼叫來看,則是R0 = L4_nilthread,R1 = ping threads,R2 = L4_NEVER。
接下來在syscall_handler中,發現是SYS_IPC的呼叫,會將caller->sp當成參數呼叫sys_ipc。
//kernel/ipc.c
void sys_ipc(uint32_t *param1)
{
/* TODO: Checking of recv-mask */
tcb_t *to_thr = NULL;
l4_thread_t to_tid = param1[REG_R0], from_tid = param1[REG_R1];
uint32_t timeout = param1[REG_R2];
/* 所以從 R0 讀取 to_tid, R1 讀取 from_tid, R2 讀取 Timeout */
/* 當 to_tid == L4_NILTHREAD 時候,表示说不發送资料,只是等待接收 */
if (to_tid == L4_NILTHREAD && timeout) { /* Timeout/Sleep */
ipc_time_t t = { .raw = timeout };
caller->state = T_INACTIVE;
ktimer_event_create((t.period.m << t.period.e) /
((1000000)/(CORE_CLOCK/CONFIG_KTIMER_HEARTBEAT)), /* millisec to ticks */
ipc_timeout, caller);
return;
}
/* 當 to_tid != L4_NILTHREAD, 就是要發送资料 */
if (to_tid != L4_NILTHREAD) {
to_thr = thread_by_globalid(to_tid);
if (to_tid == TID_TO_GLOBALID(THREAD_LOG)) {
user_log(caller);
caller->state = T_RUNNABLE;
return;
} else if ((to_thr && to_thr->state == T_RECV_BLOCKED) || to_tid == caller->t_globalid) {
/* 這邊要礭定 to_thr 的狀态是在等待接收才可以傳送 */
/* To thread who is waiting for us or sends to myself */
do_ipc(caller, to_thr);
return;
} else if (to_thr && to_thr->state == T_INACTIVE && GLOBALID_TO_TID(to_thr->utcb->t_pager) == GLOBALID_TO_TID(caller->t_globalid)) {
/* 如果thread狀态是 T_INACTIVE, 則啟動它 */
if (ipc_read_mr(caller, 0) == 0x00000003) {
/* thread start protocol */
memptr_t sp = ipc_read_mr(caller, 2);
size_t stack_size = ipc_read_mr(caller, 3);
dbg_printf(DL_IPC, "IPC: %t thread start\n", to_tid);
to_thr->stack_base = sp - stack_size;
to_thr->stack_size = stack_size;
thread_init_ctx((void *) sp, (void *) ipc_read_mr(caller, 1), to_thr);
caller->state = T_RUNNABLE;
/* Start thread */
to_thr->state = T_RUNNABLE;
return;
} else {
/* 如果没有任何 thread在等待接收,則讓自己進入等待發送階段 */
/* No waiting, block myself */
caller->state = T_SEND_BLOCKED;
caller->utcb->intended_receiver = to_tid;
dbg_printf(DL_IPC, "IPC: %t sending\n", caller->t_globalid);
return;
}
}
/* 如果 from_tid == L4_NILTHREAD, 就是不接收资料 */
if (from_tid != L4_NILTHREAD) {
/* Only receive phases, simply lock myself */
caller->state = T_RECV_BLOCKED;
/* 進入等待接收階段 */
caller->ipc_from = from_tid;
/* 設定等待的目標 */
dbg_printf(DL_IPC, "IPC: %t receiving\n", caller->t_globalid);
return;
}
caller->state = T_SEND_BLOCKED;
}從 L4_Receive_Timeout 中可以發現本次 to_tid 的值被設為 L4_NILTHREAD,因此知道這次的呼叫只是接收。
其中 sys_ipc 比較特別的一點是它包含了啟動 thread ,透過發送特定資料(thread start protocol)給目標thread就可以啟動它。
在do_ipc() 當中,一開始會先讀取tag,然後寫到目的thread的mr[0]當中。之後透過tag的內容先讀取untyped word 然後才是typed item,typed item 目前只有MapItem和GrantItem。
//kernel/ipc.c
static void do_ipc(tcb_t *from, tcb_t *to)
{
ipc_msg_tag_t tag;
...
/* 先讀取 tag */
tag.raw = ipc_read_mr(from, 0);
...
ipc_write_mr(to, 0,tag.raw);
/* Copy untyped words,透過 tag 可以知道 untyped word 的數量 */
for (untyped_idx = 1; untyped_idx < untyped_last; ++untyped_idx) {
ipc_write_mr(to, untyped_idx, ipc_read_mr(from, untyped_idx));
}
typed_item_idx = -1;
/* Copy typed words,同樣透過 tag 可以知道 typed words 數量
* FSM: j - number of byte */
for (typed_idx = untyped_idx; typed_idx < typed_last; ++typed_idx) {
uint32_t mr_data = ipc_read_mr(from, typed_idx);
/* Write typed mr data to 'to' thread */
ipc_write_mr(to, typed_idx, mr_data);
if (typed_item_idx == -1) {
/* If typed_item_idx == -1 - read typed item's tag */
typed_item.raw = mr_data;
++typed_item_idx;
} else if (typed_item.s.header & IPC_TI_MAP_GRANT) {
/* MapItem / GrantItem have 1xxx in header */
typed_data = mr_data;
/* Map/Grant action */
map_area(from->as, to->as, typed_item.raw & 0xFFFFFFC0, typed_data & 0xFFFFFFC0,
(typed_item.s.header & IPC_TI_GRANT) ? GRANT : MAP, thread_ispriviliged(from));
/* Read tag for next word */
typed_item_idx = -1;
}
/* TODO: StringItem support */
}
/* It checked if to and from stack pointer is not available */
if (!to->ctx.sp || !from->ctx.sp) {
caller->state = T_RUNNABLE;
return;
}
to->utcb->sender = from->t_globalid;
/* to->state 從 T_RECV_BLOCKED 更改為 T_RUNNABLE */
to->state = T_RUNNABLE;
/* Reset ipc_from */
to->ipc_from = L4_NILTHREAD;
((uint32_t*)to->ctx.sp)[REG_R0] = from->t_globalid;
/* If from has receive phases, lock myself */
from_recv_tid = ((uint32_t*)from->ctx.sp)[REG_R1];
if (from_recv_tid == L4_NILTHREAD) {
from->state = T_RUNNABLE;
} else {
/* 如果準備接收,更改狀態,並且透過 ipc_from 指明等待對象 */
from->state = T_RECV_BLOCKED;
from->ipc_from = from_recv_tid;
dbg_printf(DL_IPC, "IPC: %t receiving\n", from->t_globalid);
}
...
}T_SEND_BLOCKED & T_RECV_BLOCKED
當from在發送時發現to還沒有進入T_RECV_BLOCKED狀態時,from會把自己的狀態更改為T_SEND_BLOCKED。同理,當要等待message時會把自己狀態改為T_RECV_BLOCKED,因此,就會有專門的schedule來處理它們。
在kernel開始跑起來的時候,有這麼一段:
這邊是宣告一個event,每64 ticks就執行ipc_deliver。
ipc_deliver做的工作就是從thread map中找是否有T_SEND_BLOCKED或者T_RECV_BLOCKED的thread,然後檢查ipc目標是否同樣處在對應的T_RECV_BLOCKED/T_SEND_BLOCKED狀態,如果是的話,讓它們進行do_ipc()。
使用 L4 IPC
所以首先看看 L4_Msg_t類别是什么
//user/include/l4/message.h
typedef union {
L4_Word_t raw[__L4_NUM_MRS];
L4_Word_t msg[__L4_NUM_MRS];
L4_MsgTag_t tag;
} L4_Msg_t;這邊看到一個很特別的程式碼,為了增加可讀性,所以重複宣告raw & msg 這兩個同樣的變數,這樣以後使用它們的話才不會混淆使用目的。
從start_thread 中看到一些L4 IPC 的函式使用
static void __USER_TEXT start_thread(L4_ThreadId_t t, L4_Word_t ip, L4_Word_t sp, L4_Word_t stack_size)
{
L4_Msg_t msg;
L4_MsgClear(&msg);
L4_MsgAppendWord(&msg, ip);
L4_MsgAppendWord(&msg, sp);
L4_MsgAppendWord(&msg, stack_size);
L4_MsgLoad(&msg);
L4_Send(t);
}一開始宣告要傳送的message,然後進行初始化(L4_MsgClear),之後把要傳送的ITEM利用函式呼叫放進msg當中,不同的ITEM用不同的方式放入,其中包括了:
- L4_MsgAppendWord
- L4_MsgAppendMapItem
- L4_MsgAppendGrantItem
- L4_MsgAppendSimpleStringItem
- L4_MsgAppendStringItem
- L4_MsgAppendCtrlXferItem
- L4_AppendFaultConfCtrlXferItems
利用這些函式呼叫讓處理Message格式時候可以更加輕鬆。
當所有要傳送的資訊都被append進msg之後,會呼叫L4_MsgLoad(&msg)
//user/include/l4/message.h
L4_INLINE void L4_MsgLoad (L4_Msg_t *msg)
{
/* 同樣為了分隔硬體相關和非硬體相關的程式碼 */
L4_LoadMRs(0, msg->tag.X.u + msg->tag.X.t + 1, &msg->msg[0]);
}
//user/include/l4/platform/vregs.h
L4_INLINE void L4_LoadMRs(int i, int k, L4_Word_t *w)
{
if (i < 0 || k <= 0 || i + k > __L4_NUM_MRS)
return;
switch (i) {
case 0: __L4_MR0 = *w++; if (--k <= 0) break;
case 1: __L4_MR1 = *w++; if (--k <= 0) break;
case 2: __L4_MR2 = *w++; if (--k <= 0) break;
case 3: __L4_MR3 = *w++; if (--k <= 0) break;
case 4: __L4_MR4 = *w++; if (--k <= 0) break;
case 5: __L4_MR5 = *w++; if (--k <= 0) break;
case 6: __L4_MR6 = *w++; if (--k <= 0) break;
case 7: __L4_MR7 = *w++; if (--k <= 0) break;
default:
{
uint32_t *mr = __L4_Utcb()->mr;
while (k-- > 0)
*mr++ = *w++;
}
}
}這邊利用 switch 的原因是無法用 subscript operator存取。
最後透過L4_Send會呼叫硬體相關的L4_Ipc把message傳送給目標thread。
Thread
Thread Control Block
//include/thread.h
struct tcb {
//global id 是唯一的
l4_thread_t t_globalid;
l4_thread_t t_localid;
// 目前thread的執行狀態
thread_state_t state;
memptr_t stack_base;
size_t stack_size;
context_t ctx;
as_t *as;
struct utcb *utcb;
// 當處在等待接收訊息狀態時候,ipc_from表示了等待的目標
l4_thread_t ipc_from;
// 建立thread map所需要的元素
struct tcb *t_sibling;
struct tcb *t_parent;
struct tcb *t_child;
};global id 的作用在於分辨thread所使用的AS。 每個thread都有自己的AS(Address Space),而AS當中則儲存了thread所擁有的Fpage。
Context
TCB中ctx的存在是為了context switch 的時候將當下一些資訊儲存起來,以方便之後switch回來。
//include/thread.h
typedef struct {
uint32_t sp; // stack pointer
uint32_t ret; // return address
uint32_t ctl; // control register
uint32_t regs[8]; // r4 - r11
#ifdef CONFIG_FPU
uint64_t fp_regs[8]; // floating point registers
uint32_t fp_flag;
#endif
} context_t;context_t 中的regs只有8個,分別是r4 - r11,至於r0..r3, r12, lr, pc,
xpsr 設在sp當中。 其中ctl是arm 中的control register, 有三個控制項 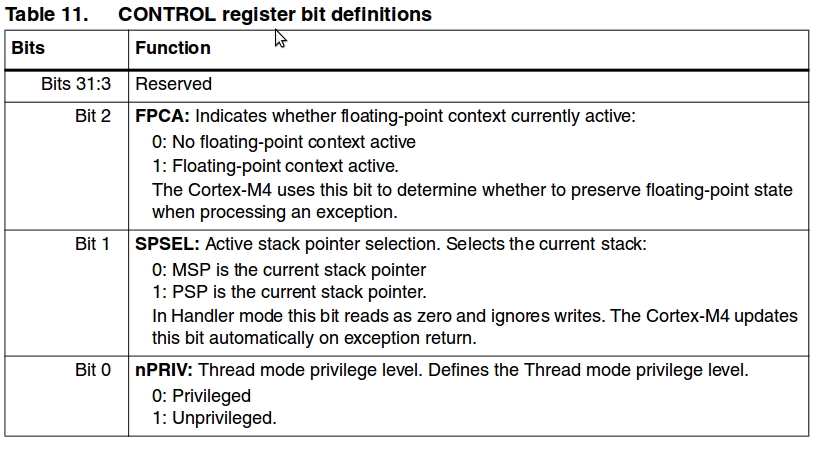
User-level Thread Control Block
//include/l4/utcb.h
struct utcb {
/* +0w */
l4_thread_t t_globalid;
uint32_t processor_no;
uint32_t user_defined_handle; /* NOT used by kernel */
l4_thread_t t_pager;
/* +4w */
uint32_t exception_handler;
uint32_t flags; /* COP/PREEMPT flags (not used) */
uint32_t xfer_timeouts;
uint32_t error_code;
/* +8w */
l4_thread_t intended_receiver;
l4_thread_t sender;
uint32_t thread_word_1;
uint32_t thread_word_2;
/* +12w */
uint32_t mr[8]; /* MRs 8-15 (0-8 are laying in
r4..r11 [thread's context]) */
/* +20w */
uint32_t br[8];
/* +28w */
uint32_t reserved[4];
/* +32w */
};- error_code 是在thread發生錯誤時候的錯誤代碼
- intended_receiver 是在進入SEND_BLOCKED 時候說明在等待發送訊息的對象
- ipc_from 是在進入RECV_BLOCKED 時候說明在等待接收對象
- mr[8]是message registers
- br[8]是buffer registers
其他的用途目前沒有在F9中看到。
Thread Create
thread_create 是kernel在syscall中接到要求create thread用來新增thread的。
tcb_t *thread_create(l4_thread_t globalid, utcb_t *utcb)
{
...
/* 這邊會先init thread,而且把tcb 空間配置好後回傳*/
thr = thread_init(globalid, utcb);
/* 呼叫create thread的thread為 parent */
thr->t_parent = caller;
/* 以下只是把thread放到 caller的child */
/* Place under */
if (caller->t_child) {
tcb_t *t = caller->t_child;
while (t->t_sibling != 0)
t = t->t_sibling;
t->t_sibling = thr;
/* thread的local id由child的數序決定,因此可能不同的thread有同樣的local id*/
thr->t_localid = t->t_localid + (1 << 6);
} else {
/* That is first thread in child chain */
caller->t_child = thr;
thr->t_localid = (1 << 6);
}
return thr;
}最後會回傳tcb,要注意的是這邊的utcb是已經配好的空間,thread_create不會幫忙配置空間,global id也是要預先獲得。
Global id獲得方式
//user/include/l4/types.h
L4_INLINE L4_ThreadId_t L4_GlobalId(L4_Word_t threadno, L4_Word_t version)
{
L4_ThreadId_t t;
t.global.X.thread_no = threadno;
t.global.X.version = version;
return t;
}所以是根據version和thread parent目前擁有的子thread數量決定的。
接下來看Thread 如何 initial。
Thread Initialization
tcb_t *thread_init(l4_thread_t globalid, utcb_t *utcb)
{
tcb_t *thr;
/* 首先從thread_table中獲得記憶體 */
thr = (tcb_t *) ktable_alloc(&thread_table);
if (!thr) {
set_caller_error(UE_OUT_OF_MEM);
return NULL;
}
/* 把thread放進thread map中 */
thread_map_insert(globalid, thr);
/* local id過後會根據所屬parent的child順序決定,因此這邊先給0x0 */
thr->t_localid = 0x0;
...
thr->as = NULL;
thr->utcb = utcb;
thr->state = T_INACTIVE;
dbg_printf(DL_THREAD, "T: New thread: %t @[%p] \n", globalid, thr);
return thr;
}目前只看到thread map在ipc_deliver中會被逐個檢查是否有recv_block & send_block 的情況。
thread的address space會在thread_space 中配置,而在 syscall 處理 create thread 的時候會在 thread_create 以後呼叫 thread_space。
void thread_space(tcb_t *thr, l4_thread_t spaceid, utcb_t *utcb)
{
/* If spaceid == dest than create new address space
* else share address space between threads
*/
if (GLOBALID_TO_TID(thr->t_globalid) == GLOBALID_TO_TID(spaceid)) {
thr->as = as_create(thr->t_globalid);
/* Grant kip_fpage & kip_ext_fpage only to new AS */
map_fpage(NULL, thr->as, kip_fpage, GRANT);
map_fpage(NULL, thr->as, kip_extra_fpage, GRANT);
dbg_printf(DL_THREAD,"\tNew space: as: %p, utcb: %p \n", thr->as, utcb);
} else {
tcb_t *space = thread_by_globalid(spaceid);
thr->as = space->as;
++(space->as->shared);
}
/* If no caller, than it is mapping from kernel to root thread
* (some special case for root_utcb)
*/
if (caller)
map_area(caller->as, thr->as, (memptr_t) utcb,
sizeof(utcb_t), GRANT, thread_ispriviliged(caller));
else
map_area(thr->as, thr->as, (memptr_t) utcb, sizeof(utcb_t), GRANT, 1);
}不是的話則用as_create從as_table (ktable)中配置一記憶體空間給thread,並且先把基本fpage(kip & kip_extra)map 給新的as。
map_area會把caller的記憶體分割後映射到thr的as。
Thread start過程
F9利用IPC來啟動一個thread,以user/root_thread.c中的start_thread為例子
static void __USER_TEXT start_thread(L4_ThreadId_t t, L4_Word_t ip, L4_Word_t sp, L4_Word_t stack_size)
{
L4_Msg_t msg;
L4_MsgClear(&msg);
L4_MsgAppendWord(&msg, ip);
L4_MsgAppendWord(&msg, sp);
L4_MsgAppendWord(&msg, stack_size);
L4_MsgLoad(&msg);
L4_Send(t);
}只要把ip, sp, stack_size透過IPC傳送給想要啟動的thread, IPC在偵測到目標thread為T_INACTIVE時候,首先會init thread 的context, 接著就把該thread的狀態改為T_RUNNABLE。
// kernel/ipc
void sys_ipc()
{
...
else if (to_thr && to_thr->state == T_INACTIVE &&
GLOBALID_TO_TID(to_thr->utcb->t_pager) == GLOBALID_TO_TID(caller->t_globalid)) {
if (ipc_read_mr(caller, 0) == 0x00000003) {
/* thread start protocol */
/* stack pointer */
memptr_t sp = ipc_read_mr(caller, 2);
/* stack size */
size_t stack_size = ipc_read_mr(caller, 3);
dbg_printf(DL_IPC, "IPC: %t thread start\n", to_tid);
to_thr->stack_base = sp - stack_size;
to_thr->stack_size = stack_size;
/* ipc_read_mr return ip here, 然後ip會被储存到pc當中 */
thread_init_ctx((void *) sp, (void *) ipc_read_mr(caller, 1), to_thr);
caller->state = T_RUNNABLE;
/* Start thread */
to_thr->state = T_RUNNABLE;
return;
}
...
}當thread狀態更改為T_RUNNABLE之後,就會被scheduler考慮進排程裡頭了。
Root Thread
ROOT THREAD是F9定義好的THREAD之一,目的在於執行user thread。
//kernel/systhread.c
void create_root_thread(void)
{
root = thread_init(TID_TO_GLOBALID(THREAD_ROOT), &root_utcb);
thread_space(root, TID_TO_GLOBALID(THREAD_ROOT), &root_utcb);
as_map_user(root->as);
thread_init_ctx((void *) &root_stack_end, root_thread, root);
root->stack_base = (memptr_t)&root_stack_start;
root->stack_size = (uint32_t)&root_stack_end - (uint32_t)&root_stack_start;
sched_slot_dispatch(SSI_ROOT_THREAD, root);
root->state = T_RUNNABLE;
}ROOT THREAD的GLOBAL ID是固定的,root_utcb是一開始就被預設放在kip section當中。 thread_space建立thread所需要用的記憶體空間 as_map_user(root->as)這部分把原本就預留的user_text, user_data和user_bss的記憶體空間包成fpage,其中user_text有三個fpage,user_data三個, user_bss一個,到這步驟,屬於root thread的fpage如下
- 區塊,fpage位置,fpage base, fpage size
- KIP,0x2000c510,0x20000400,256
- KIP,0x2000c528,0x20000500,256
- UTEXT,0x2000c540,0x2000ee00,512
- UTEXT,0x2000c558,0x2000f000,4096
- UTEXT,0x2000c570,0x20010000,2048
- UDATA,0x2000c588,0x20010800,256
- UDATA,0x2000c5a0,0x20010900,256
- UDATA,0x2000c5b8,0x20010a00,256
- UBSS,0x2000c5d0,0x20010a00,256
之所以要將這些記憶體包成fpage,原因在於root負責map USER 部分的記憶體,所以要先map給root。
接下來是thread_init_ctx,這邊看到root_stack_end,從f9.map中找到它對應0x2001a000的位置,root_thread是root thread的entry。 thread_init_ctx一開始把sp減去256,是RESERVED給r0,r1,r2,r3,r12,lr,pc,xspr這些register。
使用sp中fake context方法:sp[REG_R0],其中REG_R0 等在armv7m.h中定義。
//include/platform/armv7m.h
enum register_stack_t {
/* Saved by hardware */
REG_R0,
REG_R1,
REG_R2,
REG_R3,
REG_R12,
REG_LR,
REG_PC,
REG_xPSR
};Root thread的工作是把user的thread啟動,之後就進入休眠狀態。
在platform/stm32f4/f9_flash.ld中有一塊user_runtime,並且有紀錄開頭跟結尾的變數user_runtime_start跟user_runtime_end,這邊的作法跟Init Hook很像。會掃過一遍user_runtime中的struct,然後開始執行user
thread。
// user/root_thread.c
extern user_struct user_runtime_start[];
extern user_struct user_runtime_end[];
void __USER_TEXT __root_thread(kip_t *kip_ptr, utcb_t *utcb_ptr)
{
L4_ThreadId_t myself = {.raw = utcb_ptr->t_globalid};
char *free_mem = (char *) get_free_base(kip_ptr);
for (user_struct *ptr = user_runtime_start; ptr != user_runtime_end; ++ptr) {
L4_ThreadId_t tid;
L4_Word_t stack;
user_fpage_t *fpage = ptr->fpages;
tid = L4_GlobalId(ptr->tid + kip_ptr->thread_info.s.user_base, 2);
/* create thread */
L4_ThreadControl(tid, tid, L4_nilthread, myself, free_mem);
//在create thread時候,會從free_mem配置出utcb
free_mem += UTCB_SIZE;
/* map user_text, user_data and user_bss */
map_user_sections(kip_ptr, tid);
/* map thread stack */
L4_Map(tid, (L4_Word_t)free_mem, STACK_SIZE);
free_mem += STACK_SIZE;
stack = (L4_Word_t)free_mem;
/* map fpages */
while (fpage->base || fpage->size) {
if (fpage->base) {
L4_Map(tid, fpage->base, fpage->size);
} else {
L4_Map(tid, (L4_Word_t)free_mem, fpage->size);
fpage->base = (L4_Word_t)free_mem;
}
free_mem += fpage->size;
fpage++;
}
/* start thread */
start_thread(tid, (L4_Word_t)ptr->entry, stack, STACK_SIZE);
}
while (1)
L4_Sleep(L4_Never);
}這邊使用L4_Map將root自己的記憶體配置給user使用,而每個user在DECLARE的時候就會告知自己所需要的FPAGE位置和大小。
KProbe
Kprobes是一個kernel內建的動態狀態顯示機製,可讓開發人員不用重新編譯或者啟動kernel就可以獲得kernel的狀態訊息。KProbes是藉由硬體中斷實作,目前是透過ARMv7-M Debug架構中的Flash Patch and Breakpoint unit (FPB)完成該功能。
KProbe
Kprobe利用list儲存和管理所有被register的address,其中struct kprobe如下
struct kprobe {
void *addr; /*中斷地址*/
kprobe_pre_handler_t pre_handler; /*前處理*/
kprobe_post_handler_t post_handler; /*後處理*/
struct breakpoint *bkpt; /*硬體中斷資料結構*/
void *step_addr; /* 儲存下一個指令地址,arm cortex M 在debug mode支援single step */
struct kprobe *next; /*下一個*/
};硬體中斷資料結構儲存的內容為
struct breakpoint{
uint16_t type; /*種類分成三種NONE, SOFT, HARD */
union{
uint16_t hard_breakpoint_id; /* breakpoint id*/
uint16_t back_instr;
uint16_t raw_data;
};
uint32_t addr; /*目標地址 */
void (*enable)(struct breakpoint *b); /*根據種類指向對應的enable,disable,release功能*/
void (*disable)(struct breakpoint *b);
void (*release)(struct breakpoint *b);
};
How-to-use
===========
| Kprobes 可以透過 kprobe_register & kprobe_unregister 登記和取消登記,成功時候會回傳0,反之負數。
| Kprobes 將所有 register 的 kp 儲存在 kplist 當中,並且設定相關硬體 register
```c
int kprobe_register(struct kprobe *kp)
{
int ret;
kp->addr = (void *)((uint32_t) kp->addr & ~(1UL)); /*把最後一bit設為0 */
if (is_thumb32(*(uint16_t *) kp->addr)) /* 支援thumb */
kp->step_addr = kp->addr + 4; /*這邊是下一個指令地址*/
else
kp->step_addr = kp->addr + 2;
ret = kprobe_arch_add(kp);
if (ret < 0)
return -1;
kplist_add(kp); /* 加入到 kplist中 */
return 0;
}register過程中會把kp對應的地址設定到FPB單位中並且啟動FPB。
//platform/kprobe_arc.c
int kprobe_arch_add(struct kprobe *kp)
{
struct kprobe *found = kplist_search(kp->addr);
struct breakpoint *b;
/*
* If there is no kprobe at this addr, give it a new bkpt,
* otherwise share the existing bkpt.
*/
if (found == NULL) {
b = breakpoint_install((uint32_t) kp->addr);
if (b != NULL) {
kp->bkpt = b;
enable_breakpoint(b);
} else
goto arch_add_error;
} else {
kp->bkpt = found->bkpt;
}
return 0;
arch_add_error:
return -1;
}斷點設定方法為breakpoint_install,而breakpoint_install會呼叫 get_avail_breakpoint
//platform/breakpoint.c
static struct breakpoint *get_avail_breakpoint(uint32_t addr)
{
int i;
for (i = 0; i < BKPT_MAX_NUM; i++) {
if (breakpoints[i].type == BKPT_NONE) /* 檢查空的,然後設定 */
return breakpoint_config(i, addr);
}
return NULL;
}在 breakpoint_config中,會透過 addr判斷是否breakpoint属性
透過記憶體位置圖0x20000000 以下的地址屬於程式碼區塊,其他的是外接口等,所以得知只有程式碼屬於hard breakpoint,其他的都由軟體虛擬出來的斷點處理。 這邊只觀察hard breakpoint,所以是hard_breakpoint_config
//platform/breakpoint-hard.c
struct breakpoint *hard_breakpoint_config(uint32_t addr, struct breakpoint *b)
{
if (breakpoint_type_by_addr(addr) == BKPT_HARD) {
int _hard_breakpoint_id = get_avail_hard_breakpoint();
int breakpoint_id = get_breakpoint_id(b);
if (breakpoint_id >= 0 && _hard_breakpoint_id >= 0) {
hard_breakpoints[_hard_breakpoint_id] = breakpoint_id;
b->type = BKPT_HARD;
b->addr = addr;
b->hard_breakpoint_id = _hard_breakpoint_id;
b->enable = hard_breakpoint_enable;
b->disable = hard_breakpoint_disable;
b->release = hard_breakpoint_release;
return b;
}
}
return NULL;
}將所有的值儲存好之後,透過這邊儲存的enable function去啟動該kprobe。
#define FPB_COMP_ENABLE (uint32_t) (1 << 0)
#define FPB_COMP_REPLACE_LOWER (uint32_t) (1 << 30)
#define FPB_COMP_REPLACE_UPPER (uint32_t) (2 << 30)
/* FP_COMPx: 000:COMP_ADDR:00 */
#define FPB_COMP_ADDR_MASK 0x1FFFFFFC
static void hard_breakpoint_enable(struct breakpoint *b)
{
uint32_t addr = b->addr;
if (IS_UPPER_HALFWORLD(addr)) { /* ??? */
*(FPB_COMP + b->hard_breakpoint_id) = FPB_COMP_REPLACE_UPPER | (addr & FPB_COMP_ADDR_MASK) | FPB_COMP_ENABLE;
} else {
*(FPB_COMP + b->hard_breakpoint_id) = FPB_COMP_REPLACE_LOWER | (addr & FPB_COMP_ADDR_MASK) | FPB_COMP_ENABLE;
}
}這邊addr會被去掉前面 3 個bit 和後面 2 個bit,最後一個bit 為enable。
Debug Handler
當FPB比對addr相同時候,會傳送bkpt指令給處理器,然後處理器會進入debug_handler,F9的debug_handler為debugmon_handler
//platform/hw_debug.c
void debugmon_handler(void)
{
/* select interrupted stack */
/* 透過地址比對獲知kprobe addr的模式,然後选擇對應的stack */
__asm__ __volatile__("and r0, lr, #4");
__asm__ __volatile__("cmp r0, #0");
__asm__ __volatile__("ite eq");
__asm__ __volatile__("mrseq r0, msp");
__asm__ __volatile__("mrsne r0, psp");
/* save r4-r11 */
__asm__ __volatile__("push {r4-r11}");
__asm__ __volatile__("mov r1, sp");
/*
* arch_kprobe_handler(uint32_t *stack, uint32_t *kp_regs)
* r0 = r0-r3,r12,lr,pc,psr
* r1 = r4-r11
*/
__asm__ __volatile__("push {lr}"); //储存lr,才能回到之前的指令
__asm__ __volatile__("bl arch_kprobe_handler");
__asm__ __volatile__("pop {lr}");
/* override r4-r11 */
__asm__ __volatile__("pop {r4-r11}");
/* NOTE: No support stack modification for the time being */
/* 處理结束,回到原本地址 */
__asm__ __volatile__("bx lr");
}
//platform/kprobes-arch.c
void arch_kprobe_handler(uint32_t *stack, uint32_t *kp_regs)
{
/*
* For convenience currently we assume all cpu single-step is
* enabled/disabled by arch_kprobe_handler.
*
* To execute instruction at the probed address, we have to disable
* breakpoint before return from handler, and re-enable it in the
* next instruction.
*/
if ((*SCB_DFSR & SCB_DFSR_DWTTRAP)) {
panic("DWT Watchpoint hit\n");
} else if ((*SCB_DFSR & SCB_DFSR_BKPT)) {
/* 首先去執行 prehandler */
kprobe_prebreak(stack, kp_regs);
/* Clear BKPT status bit */
*SCB_DFSR = SCB_DFSR_BKPT;
/* 這邊enable single step的原因在於要進入下方else if做出post_handler */
cpu_enable_single_step();
/* 需要把breakpoint解除才能夠執行probed address */
kprobe_breakpoint_disable(stack);
} else if (*SCB_DFSR & SCB_DFSR_HALTED) {
/* 執行 posthandler */
kprobe_postbreak(stack, kp_regs);
/* Clear HALTED status bit */
*SCB_DFSR = SCB_DFSR_HALTED;
/* 解除single step */
cpu_disable_single_step();
/* 把breakpoint重新啟動 */
kprobe_breakpoint_enable(stack);
} else {
/*
* sometimes DWT generates faults
* without setting SCB_DFSR_DWTTRAP
*/
}
}所以整個流程為
- 當FPB發現是probed address時候,在probed address前加入breakpoint。
- 處理器發現breakpoint,進入debugmon_handler, debugmon_handler進入arch_kprobe_handler。
- arch_kprobe_handler進入”else if ((*SCB_DFSR & SCB_DFSR_BKPT)) “,執行prehandler,清除狀態register,啟動single step,清除probed address breakpoint。
- handler結束,FPB發現probed address,可是這時候breakpoint已經解除,所以probed address可以執行。
- probed address指令執行結束,可是目前是single step狀態,所以再次進入debugmon_handler,進入arch_kprobe_handler。
- arch_kprobe_handler這次進入”else if (*SCB_DFSR & SCB_DFSR_HALTED)“,執行posthandler,清除狀態register,清除single step,重新啟動probed address breakpoint。
Example – sampling
第一次給於指令’p’的時候,會在ktimer_handler中register kprobe,當每次ktimer_handler被呼叫時候,sampling會記錄kernel的一些相關訊息,在下次收到’p’ 指令時將它們輸出。
//kernel/sampling-kdb.c
extern void ktimer_handler(void);
void kdb_show_sampling(void)
{
...
static int init = 0;
static struct kprobe k;
if (init == 0) { //第一次會register kprobe
dbg_printf(DL_KDB, "Init sampling...\n");
sampling_init();
sampling_enable();
init++;
//下面是正確的register kprobe範例
k.addr = ktimer_handler;
k.pre_handler = sampling_handler;
k.post_handler = NULL;
kprobe_register(&k);
return;
}
...
}KTimer
L4將硬體中斷當成IPC message轉交給user-level thread處理,該thread需要跟kernel register成為特定硬體中斷的handler。每個硬體中斷只轉交給一個Handler,但是一個thread可以成為多個中斷的handler。
在L4中,timer ticks interrupt是唯一一個被內部處理的中斷,但在F9中,此中斷依然是繼續使用L4 中其它中斷處理方法。而Ktimer 就是F9轉交timer ticks interrupt的handler。
KTIMER相關設定
- CONFIG_KTIMER_HEARTBEAT:每個ktimer tick的硬體cycles
- CONFIG_KTIMER_MINTICKS:time event的最小ktimer ticks
- CONFIG_KTIMER_TICKLESS:tickless啟用
一開始的 systick handler 是 __ktimer_handler
//kernel/ktimer.c
void __ktimer_handler(void)
{
++ktimer_now; //目前的time
if (ktimer_enabled && ktimer_delta > 0) {
++ktimer_time;
--ktimer_delta; //利用counting down方式的timer
if (ktimer_delta == 0) {
ktimer_enabled = 0;
ktimer_time = ktimer_delta = 0;
//ktimer_delta 等於0的時候,把相關event加入排程。
softirq_schedule(KTE_SOFTIRQ);
}
}
}ktimer_delta是下一個event發生的倒數時間,倒數完畢後會排程softirq。
在ktimer初始化時候,宣告了KTE_SOFTIRQ的handler。
void ktimer_event_init()
{
ktable_init(&ktimer_event_table);
ktimer_init();
// softirq that belongs to KTE_SOFTIRQ will be handled by ktimer_event_handler
softirq_register(KTE_SOFTIRQ, ktimer_event_handler);
}
...
// INIT HOOK
INIT_HOOK(ktimer_event_init, INIT_LEVEL_KERNEL);ktimer的event list是根據時間排序,從最近到最遠,所以在event_handler當中只需要從前面開始找出delta = 0的event。
void ktimer_event_handler()
{
ktimer_event_t *event = event_queue;
ktimer_event_t *last_event = NULL;
ktimer_event_t *next_event = NULL;
uint32_t h_retvalue = 0;
if (!event_queue) {
/* That is bug if we are here */
...
}
/* 尋找最後一個delta = 0的event */
do {
event = event->next;
} while (event && event->delta == 0);
// last_event->delta != 0
last_event = event;
/* All rescheduled events will be scheduled after last event */
// 所以event 是要處理的event, event_queue把要處理的event 拿掉了
event = event_queue;
event_queue = last_event;
/* walk chain */
do {
//event->handler應該在register的時候就要儲存
h_retvalue = event->handler(event);
next_event = event->next;
// 下一次的event時間,所以重新排進event_queue中
if (h_retvalue != 0x0) {
dbg_printf(DL_KTIMER,
"KTE: Handled and rescheduled event %p @%ld\n",
event, ktimer_now);
ktimer_event_schedule(h_retvalue, event);
} else {
//不再需要發生了,所以把記憶體free掉
dbg_printf(DL_KTIMER,
"KTE: Handled event %p @%ld\n",
event, ktimer_now);
ktable_free(&ktimer_event_table, event);
}
event = next_event; /* Guaranteed to be next
regardless of re-scheduling */
} while (next_event && next_event != last_event);
if (event_queue) {
/* Reset ktimer */
// 重新把ktimer設定好,並且把ktimer_delta設定成下一個event_queue的delta
ktimer_enable(event_queue->delta);
}
}特別的一點是透過next_event先儲存下一個event,避免在ktimer重新排程的時候選擇到新排程next的event。
//kernel/ktimer.c
static void ktimer_enable(uint32_t delta)
{
if (!ktimer_enabled) {
ktimer_delta = delta;
ktimer_time = 0;
ktimer_enabled = 1;
}
} //kernel/ktimer.c
int ktimer_event_schedule(uint32_t ticks, ktimer_event_t *kte)
{
long etime = 0, delta = 0;
ktimer_event_t *event = NULL, *next_event = NULL;
if (!ticks)
return -1;
// 每次enable, ktimer_time 歸零,所以tick是距離最近的ktimer_handler的時間開始計算
// 要注意的是最近的ktimer_handler不包含本次
ticks -= ktimer_time;
kte->next = NULL;
//分成兩個情況,event_queue裡面是否有event
if (event_queue == NULL) {
/* All other events are already handled, so simply schedule
* and enable timer
*/
...
//設定kte->delta,然後放進event_queue
kte->delta = ticks;
event_queue = kte;
//重設ktimer
ktimer_enable(ticks);
} else {
next_event = event_queue;
//因為event_queue原本已經排序好,所以只需要找出擺放位置就可以了
if (ticks >= event_queue->delta) {
do {
event = next_event;
//etime是到目前event所需要的delta
etime += event->delta;
//delta是所要倒數的時間與前一個event的時間差
//例如queue原本有A,A的delta是20,而B需要倒數30,則B的delta是10
delta = ticks - etime;
next_event = event->next;
} while (next_event && ticks > (etime + next_event->delta));
/* Insert into chain and recalculate */
event->next = kte;
} else {
event_queue = kte;
delta = ticks;
/* Reset timer */
ktimer_enable(ticks);
}
/* Chaining events */
if (delta < CONFIG_KTIMER_MINTICKS)
delta = 0;
kte->next = next_event;
kte->delta = delta;
ktimer_event_recalc(next_event, delta);
}
return 0;
}這邊看到最後會呼叫ktimer_event_recalc(next_event, delta),next_event是指向kte之後一個event,delta是kte的delta,所以看得出這功能是重新計算kte之後的event->delta。
How-to Use KTimer
使用方法很簡單,只是create ktimer event就可以了。
//kernel/ktimer.c
int ktimer_event_create(uint32_t ticks, ktimer_event_handler_t handler, void *data)
{
ktimer_event_t *kte;
if (!handler)
return -1;
kte = (ktimer_event_t *) ktable_alloc(&ktimer_event_table);
/* No available slots */
if (kte == NULL)
return -1;
kte->next = NULL;
kte->handler = handler;
kte->data = data;
return ktimer_event_schedule(ticks, kte);
}ticks是指距離上次ktimer_handler多少個ticks後要發生,handler是發生時候處理的function,data是傳遞給handler的參數。 create event從ktimer_event_table中獲得記憶體之後把資料儲存起來然後開始排程。
效能表現
Miscellaneous
Kernel Interface Page
在L4中,KIP包含了API、kernel版本資訊、system descriptor including memory descriptor、system call link,剩下的部份還未定義。這個page是一個mircokernel object,在AS建立時會直接映射到每個AS。他不是被pager映射,而且不能被map或grant到其他的AS,也不能被unmap。新AS的創建者可以決定要讓KIP被映射到哪些位置,而這些位置在AS的生命週期中會一直存在,任意的thread都能透過KERNELINTERFACE這個system call取得這些位置。
至於F9中實作KIP中的一部分,以下是KIP在F9中的結構:
/* include/l4/kip_types.h */
// 我將F9中沒有用到或沒有實作的部份先拿掉
typedef struct {
uint32_t base; /* Last 6 bits contains poolid */
uint32_t size; /* Last 6 bits contains tag */
} kip_mem_desc_t;
typedef union {
struct {
uint8_t version;
uint8_t subversion;
uint8_t reserved;
} s;
uint32_t raw;
} kip_apiversion_t;
typedef union {
struct {
uint32_t reserved : 28;
uint32_t ww : 2;
uint32_t ee : 2;
} s;
uint32_t raw;
} kip_apiflags_t;
typedef union {
struct {
uint16_t memory_desc_ptr; // 從kip開頭到mem_desc的offset
uint16_t n;
} s;
uint32_t raw;
} kip_memory_info_t;
typedef union {
struct {
uint32_t user_base;
uint32_t system_base;
} s;
uint32_t raw;
} kip_threadinfo_t;
struct kip {
uint32_t kernel_id;
kip_apiversion_t api_version;
kip_apiflags_t api_flags;
uint32_t kern_desc_ptr;
kip_memory_info_t memory_info;
kip_threadinfo_t thread_info;
};- memory_info - 紀錄memory pool的位置以及數量
- thread_info - 紀錄可以用在system thread以及user thread上最小的thread number
Init Hook
F9-kernel用了一個global initialization
hook的技巧,這個技巧可以在任意地方定義一段要在系統初始化時執行的code。一個init hook會在特定的run
level被呼叫,hook可以保證依據level順序呼叫,但不能保證在同一個level中呼叫的順序,下面是一個init hook的結構:
/* include/init_hook.h */
typedef struct {
unsigned int level;
init_hook_t hook;
const char *hook_name;
} init_struct;其中包含要在哪個level呼叫、要執行的code位置、名稱,宣告這個結構的方法如下:
/* include/init_hook.h */
#define INIT_HOOK(_hook, _level) \
const init_struct _init_struct_##_hook __attribute__((section(".init_hook"))) = { \
.level = _level, \
.hook = _hook, \
.hook_name = #_hook, \
};使用INIT_HOOK這個macro可以宣告一個init_struct,並且將這個結構放到.init_hook
section中,接著觀察linker script:
/* loader/loader.ld */
SECTIONS {
.text 0x08000000:
{
KEEP(*(.isr_vector))
. = TEXT_BASE;
text_start = .;
*(.text*)
*(.rodata*)
.init_hook_start = .;
KEEP(*(.init_hook))
init_hook_end = .;
text_end = .;
} > MFlash
...
}在KEEP(*(.init_hook))前後各紀錄了一個位置,init_hook_start會是section
.init_hook的開始,init_hook_end會是section
.init_hook的結束。
在F9-kernel中已經有一些地方使用到INIT_HOOK:
$ grep INIT_HOOK kernel/* platform/*
kernel/kdb.c:INIT_HOOK(kdb_init, INIT_LEVEL_KERNEL);
kernel/kprobes.c:INIT_HOOK(kprobe_init, INIT_LEVEL_KERNEL);
kernel/ksym.c:INIT_HOOK(ksym_init, INIT_LEVEL_KERNEL_EARLY);
kernel/ktimer.c:INIT_HOOK(ktimer_event_init, INIT_LEVEL_KERNEL);
kernel/memory.c:INIT_HOOK(memory_init, INIT_LEVEL_KERNEL_EARLY);
kernel/sched.c:INIT_HOOK(sched_init, INIT_LEVEL_KERNEL_EARLY);
kernel/syscall.c:INIT_HOOK(syscall_init, INIT_LEVEL_KERNEL);
kernel/thread.c:INIT_HOOK(thread_init_subsys, INIT_LEVEL_KERNEL);
platform/debug_device.c:INIT_HOOK(dbg_device_init_hook, INIT_LEVEL_PLATFORM);接著看一下init_hook_start跟init_hook_end的值,並觀察剛剛定義的init_struct是放在哪邊:
$ arm-none-eabi-readelf -s f9.elf | grep "init_hook_start|init_hook_end" -E
765: 08005924 0 NOTYPE GLOBAL DEFAULT 1 init_hook_end
934: 080058b8 0 NOTYPE GLOBAL DEFAULT 1 init_hook_start
$ arm-none-eabi-objdump -d f9.elf | grep init_struct
080058b8 <_init_struct_dbg_device_init_hook>:
080058c4 <_init_struct_ktimer_event_init>:
080058d0 <_init_struct_memory_init>:
080058dc <_init_struct_sched_init>:
080058e8 <_init_struct_syscall_init>:
080058f4 <_init_struct_thread_init_subsys>:
08005900 <_init_struct_kdb_init>:
0800590c <_init_struct_kprobe_init>:
08005918 <_init_struct_ksym_init>:可以發現0x080058b8~0x08005924剛好就是剛剛定義的init_struct內容(一個init_struct的大小是12byte,所以最後一個是0x8005918+12=0x8005924),而且這些結構會是連續的存放在一起。剩下的就是如何執行這些code:
/* kernel/init.c */
extern const init_struct init_hook_start[];
extern const init_struct init_hook_end[];
static unsigned int last_level = 0;
int run_init_hook(unsigned int level)
{
unsigned int max_called_level = last_level;
for (const init_struct *ptr = init_hook_start; ptr != init_hook_end; ++ptr)
if ((ptr->level > last_level) && (ptr->level <= level)) {
max_called_level = MAX(max_called_level, ptr->level);
ptr->hook();
}
last_level = max_called_level;
return last_level;
}這段程式會從init_hook_start開始掃過一遍,當發現一個hook的level是大於上次呼叫run_init_hook而且小於等於這次要run的level時,就執行對應的hook
function,並且更新最大呼叫過的level。
KTable
ktable是一套快速的物件管理機制,結構如下:
struct ktable {
char *tname;
bitmap_ptr_t bitmap;
ptr_t data;
size_t num;
size_t size;
};
typedef struct ktable ktable_t;- tname : table名稱
- bitmap : 紀錄table的使用情況
- data : 實際存放資料的區域
- num : 總共有幾個區塊
- size : 每個區塊的大小
接著是宣告ktable的方法,給予要存放在ktable中的型態、ktable的名字、以及需要的大小:
// 宣告一個ktable
// $ arm-none-eabi-readelf f9.elf -s | grep fpage_table
// 263: 10000000 32 OBJECT LOCAL DEFAULT 8 kt_fpage_table_bitmap
// 265: 2000c4e0 6144 OBJECT LOCAL DEFAULT 4 kt_fpage_table_data
#define DECLARE_KTABLE(type, name, num_) \
DECLARE_BITMAP(kt_ ## name ## _bitmap, num_); \
static __KTABLE type kt_ ## name ## _data[num_]; \
ktable_t name = { \
.tname = #name, \
.bitmap = kt_ ## name ## _bitmap, \
.data = (ptr_t) kt_ ## name ## _data, \
.num = num_, .size = sizeof(type) \
}ktable有提供下列的API可供使用:
// 將kt中的bitmap全部設為0
void ktable_init(ktable_t *kt);
// 檢查第i個元素是否已經被配置
int ktable_is_allocated(ktable_t *kt, int i);
// 配置第i個元素,回傳元素的位置
void *ktable_alloc_id(ktable_t *kt, int i);
// 配置到第一個free的元素,回傳元素的位置
void *ktable_alloc(ktable_t *kt);
// 釋放元素
void ktable_free(ktable_t *kt, void *element);
// 取得該元素位在ktable內的id
uint32_t ktable_getid(ktable_t *kt, void *element);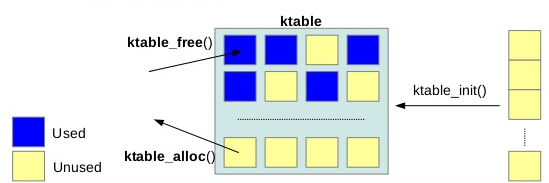
Bitmap
- bit array(bitmap, bitset, bit string, bit vector)是一種緊湊儲存位元的陣列結構,可以用來實作簡單的set結構。在硬體上操作bit-level時,bitmap是一種很有效的方法,一個典型的bitmap會儲存kw個位元,w代表一個單位需要w個位元(byte、word),k則是一個非負的整數,如果w無法被要儲存的位元整除,則有些空間會因為內部片段被浪費。
定義
bitmap會從某一個domain mapping到一個集合{0, 1},這個值可以代表valid/invalid、dark/light等等,重點在只會有兩個可能的值,所以可以被存在一個位元中。
基本操作
雖然大部分的機器無法取得或操作記憶體中的單一位元,但是可以透過bitwise操作一個word進而改變單一位元的資料:
- OR可以用來set一個位元為1:11101010 OR 00000100 = 11101110(set 3rd bit 1)
- AND可以用來set一個位元為0:11101010 AND 11111101 = 11101000(set 2nd bit 0)
- AND可以用來判斷某一個位元是否為1:11101010 AND 00000001 = 0(check 1st bit is 1)
- XOR可以用來toggle一個位元:11101010 XOR 00000100 = 11101110(toggle 3rd bit)
- NOT用來invert:NOT 11101010 = 00010101
只要n/w個bitwise operation用來算出兩個相同大小bitmap的union、intersection、difference、complement
for i from 0 to n/w-1
complement[i] := not a[i]
union[i] := a[i] or b[i]
intersection[i] := a[i] and b[i]
difference[i] := a[i] and (not b[i])如果要iterate bitmap中的所有bit,只要用一個雙層的迴圈就能有效率的掃完,只需要n/w次的memory access
for i from 0 to n/w-1
index := 0 // if needed
word := a[i]
for b from 0 to w-1
value := word and 1 ≠ 0
word := word shift right 1
// do something with value
index := index + 1 // if neededBit-banding
bit-banding會將一塊較大記憶體中的word對應到一個較小的bit-band區域中的單一bit,例如寫到其中一個alias,可以set或是clear一個bit-band區域中對應的bit。 這使得bit-band區域中每一個獨立的bit都可以透過LDR指令搭配一個word-aligned的地址進行存取,也能讓每一個獨立bit被直接toggle,而不須經過read-modify-write的指令操作。
處理器的memory map包含了兩塊bit-band區域,分別是在SRAM以及Peripheral中最低位的1MB。
System bus interface包含了一個bit-band的存取邏輯:
- remap一個bit-band alias到bit-band區域
- 讀取時,會將requested bit放在回傳資料的Least Significant Bit中
- 寫入時,會將read-modify-write轉換成一個atomic的動作
- 處理器在bit-band操作中不會stall,除非試圖在bit-band操作中存取system bus
記憶體中有兩塊32MB的alias對應到兩塊1MB的bit-band區域:
- 32MB可存取的SRAM alias區域對應到1MB的bit-band SRAM區域
- 32MB可存取的peripheral alias區域對應到1MB的bit-band peripheral區域
有一個mapping公式可以將alias轉換成對應的bit-band位置
bit_word_offset = (byte_offset x 32) + (bit_number × 4)
bit_word_addr = bit_band_base + bit_word_offset- bit_word_offset是target bit在bit-band區域中的位置
- bit_word_addr是target bit在alias中對應的地址
- bit_band_base是alias區域的起始位置
- byte_offset是target bit在bit-band區域中的第幾個byte
- bit_number是target bit的bit位置,從0到7
範例如下:
- The alias word at 0x23FFFFE0 maps to bit [0] of the bit-band byte at 0x200FFFFF: 0x23FFFFE0 = 0x22000000 + (0xFFFFF32) + 04.
- The alias word at 0x23FFFFFC maps to bit [7] of the bit-band byte at 0x200FFFFF: 0x23FFFFFC = 0x22000000 + (0xFFFFF32) + 74.
- The alias word at 0x22000000 maps to bit [0] of the bit-band byte at 0x20000000: 0x22000000 = 0x22000000 + (032) + 04.
- The alias word at 0x2200001C maps to bit [7] of the bit-band byte at 0x20000000: 0x2200001C = 0x22000000 + (032) + 74.
- bit-band[0x20000000] <-> alias0x22000000~0x2200001C
- bit-band 0x20000000[0]-0x20000000[1]-0x20000000[2]-0x20000000[3]-0x20000000[4]
- alias 0x22000000 -0x20000004 -0x20000008 -0x2000000C -0x20000010
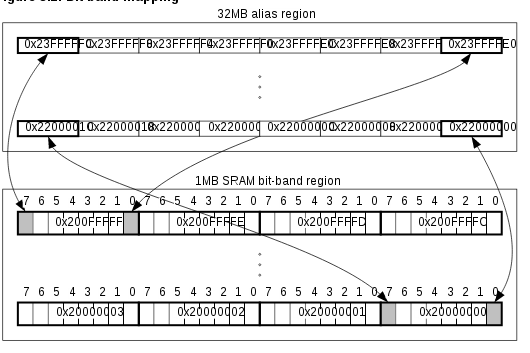
直接存取alias
直接寫一個word到alias上與target
bit的read-modify-write動作有同樣效果,Bit[0]代表要寫入target
bit的值,Bit[31:1]沒有用處,所以寫入0x01跟0xFF是一樣的,都會寫入1到target
bit;寫入0x00跟0x0E是一樣的,都會寫入0到target
bit。
從alias讀取一個word會得到0x01或是0x00,Bit[31:1]會為0
F9-kernel(Bitmap)
Bit-band bitmap被放在AHB SRAM中,使用BitBang地址存取bit,使用bitmap cursor(type bitmap_cusor_t)iterate bitmap。
/* include/lib/bitmap.h */
// 宣告一塊bitmap
#define DECLARE_BITMAP(name, size) \
static __BITMAP uint32_t name [ALIGNED(size, BITMAP_ALIGN)];
// ADDR_BITBAND指的是target bit所在byte對應到的align,還沒加上bit_number
// ((ptr_t) addr) & 0xFFFFF) 可以抓出addr在bit-band區域中的第幾個byte
#define BITBAND_ADDR_SHIFT 5
#define ADDR_BITBAND(addr) \
(bitmap_cursor_t) (0x22000000 + \
((((ptr_t) addr) & 0xFFFFF) << BITBAND_ADDR_SHIFT))
#define BIT_SHIFT 2
// bitmap_cursor是加上bit_number後的值,也就是target bit正確的align
#define bitmap_cursor(bitmap, bit) \
((ADDR_BITBAND(bitmap) + (bit << BIT_SHIFT)))
// bitmap_cursor_id可以取得bit_number
// ((1 << (BITBAND_ADDR_SHIFT + BIT_SHIFT)) - 1) 取得 0b1111111 也就是七位的mask,與cursor進行完AND操作並右移兩位後,會留下兩位的byte_offset以 及bit_number,也就是BBXXX(B:byte_offset、X:bit_number)
#define bitmap_cursor_id(cursor) \
(((ptr_t) cursor & ((1 << (BITBAND_ADDR_SHIFT + BIT_SHIFT)) - 1)) >> BIT_SHIFT)
// bitmap_cursor_goto_next 可以把cursor往前推一格(+= 4)
#define bitmap_cursor_goto_next(cursor) \
cursor += 1 << BIT_SHIFT
// for_each_in_bitmap 可以從某一個bitmap的start開始訪問完一塊bitmap
#define for_each_in_bitmap(cursor, bitmap, size, start) \
for (cursor = bitmap_cursor(bitmap, start); \
bitmap_cursor_id(cursor) < size; \
bitmap_cursor_goto_next(cursor))- bitmap_set_bit(bitmap_cursor_t cursor) - 將cursor設為1
- bitmap_clear_bit(bitmap_cursor_t cursor) - 將cursor設為0
- bitmap_get_bit(bitmap_cursor_t cursor) - 取得cursor值
- bitmap_test_and_set_bit(bitmap_cursor_t cursor) - 測試cursor是否被使用並設為1
在 STM32F4-Discovery 平台上執行
需要的套件:
- arm-none-eabi- toolchain,必須支援Cortex-M4F
- libncurses5-dev
- stlink
步驟:
- git clone https://github.com/f9micro/f9-kernel.git f9-kernel
- cd f9-kernel
- make config(使用預設設定即可)
- make
- 將 STM32F4-Discovery 接上電腦
- make flash
KDB(in-kernel debugger)
F9中內建一套除錯工具,預設是會在開機時啟動,目前支援以下指令:
- a:dump address spaces
- m:dump memory pools
- t:dump threads
- s:show softriqs
- n:show timer(now)
- e:dump ktimer events
- K:print kernel tables
使用步驟:
- 預設會使用USART4:PA0(TX), PA1(RX),所以先將pin腳接上,白線接PA0、綠線接PA1、黑線接GND
- 確認USB連上電腦
- screen /dev/ttyUSB0 115200 8n1

Troubleshooting
- 無法make flash - 電腦要先連接上STM32F4Discovery才能進行燒錄
- 沒有
screen- 執行sudo apt-get install screen - screen連接失敗 - 執行sudo screen /dev/ttyUSB0 115200 8n1
- screen傳輸的資料有問題 - 重新接線,重新啟動STM32F4
- 可以改用neocon,支援自動連線,會比screen方便(by jserv)
- neocon 在 mac os x 10.9.2 也能跑(by Benux Wei)
- 打dmesg再次確認ttyUSB0的訊息是否正確(by Wen)
- screen連接成功後,在 “Press ‘?’ to print KDB
menu”之後按下任何鍵都没有反應,可是按reset有反應。
- 重新config後就沒問題了,應該是有修改到config
- 要怎麼把輸出畫面往上拉?
Ctrl-A+[切換到copy模式就能用滾輪拉動或是Ctrl-B、Ctrl-F
參考資料
- http://www.slideshare.net/jserv/f9-microkernel
- http://www.slideshare.net/vh21/2014-0109f9kernelktimer
- ARM System Developer’s Guide : Designing and Optimizing System Software
- Kernel Interface Page
- http://www.l4ka.org/l4ka/l4-x2-r7.pdf
- Bitmap
- http://en.wikipedia.org/wiki/Bit_array
- ARM Information Center(2.5. Bit-banding)
- Init Hook
- http://kunyichen.wordpress.com/2014/04/18/f9-kernel-%E4%B9%8B-init_hook
- https://github.com/f9micro/f9-kernel/blob/master/Documentation/init-hooks.txt
- MPU
- Overview
- http://www.ertos.nicta.com.au/research/l4/microkernels.pml
- Wikipedia(Microkernel)
- Wikipedia(L4_microkernel)
- IPC
- http://www.l4ka.org/l4ka/l4-x2-r7.pdf
- Thread
- http://www.st.com/web/en/resource/technical/document/programming_manual/DM00046982.pdf page 24
- KProbe
- http://www.arm.com/files/pdf/introToCortex-M3.pdf page 8
- http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ddi0337h/BABGEDIG.html
- http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ddi0439b/CACIEIBA.html
- http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ddi0439d/CEGJGDCJ.html
- Interrupt Request

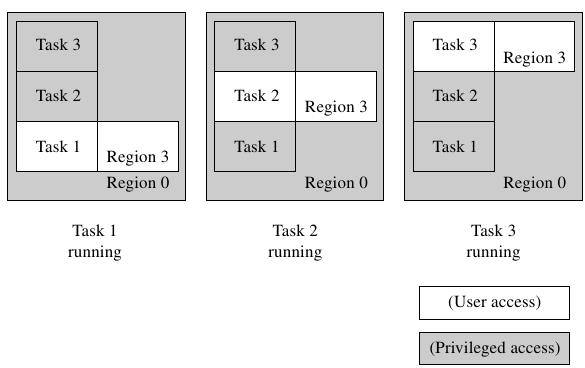{kind=link}