uClinux
協作者
- 2015 年春季
- 林建宏, 黃呂源, 柳冠宇, 柯翔元, 鄭峰盛, mshang, 楊孟勳
- 2014 年春季
- 竹內宏輝, 陳勁龍, 賀祐農
uClinux架構&特性
uClinux設計的目的即是為了能運作在缺乏MMU(memory management unit)的微控制器上(microcontroller),這也是為何稱作uClinux,uC指的就是微控制器。基本上其與linux架構相同,但因缺乏MMU而有不同特性,其中差異如下所示:
使用uClibc
uClibc比起glibc更小,且支援no-mmu環境運行。(不過其實uClinux官方也有提供使用glibc版本的uClinux)
缺乏記憶體管理(memory management)
以往的Linux中,記憶體管理藉由虛擬記憶體來實踐(virtual memory, VM),而虛擬記憶體則透過MMU來實作。然而uClinux即是為了在no-MMU環境下運行而生,既缺乏MMU也無法實作虛擬記憶體,故也不支援swap和分頁(paging)的機制。所有行程(process)所需的記憶體,必須在硬體啟動時分配好。一個行程在執行前,系統必須為行程分配足夠的連續位址空間,然後全部載入到記憶體的連續空間中,並且無法在運行(run-time)時擴展其可用的記憶體空間。
也由於缺乏MMU,沒有記憶體保護機制,即便具有MPU(memory protection unit)也無法保證不會產生錯誤。系統kernel與所有的行程皆被分配在全域記憶體(global pool)中,錯誤的記憶體操作可能導致其他程序崩潰,甚至破壞kernel。
記憶體分配
uClinux使用的記憶體分配方式為page_alloc2,或稱kmalloc2。其實這兩者概念上是相同的,只是實作的程式碼不同。另外在linux-2.0.x主要使用kmalloc2,後來到了linux-2.4.x則使用page_alloc2(kmalloc2被合併到slab.c中),而其後面的2所代表的是並非使用power of 2記憶體分配法(相較於page_alloc、kmalloc)。在uClinux中,若使用power of 2記憶體分配法的話,會造成大量記憶體被浪費。舉個經典的例子來說,若一個行程需要33KB,以power of 2分配的話,系統會給此行程64KB的空間,其中有31KB被浪費。若以page_alloc2/kmalloc2方式分配,一個頁(page)的大小是4KB,以前例來看則會分配36KB記憶體給該行程,僅3KB被浪費。此外,page_alloc2/kmalloc2也提供了避免造成記憶體碎片化的機制,若超過8KB(即兩個頁)的需求則從free memory底部開始分配,小於8KB的則從free memory的起始處開始分配。
順帶一提,kmalloc2與page_alloc2在中文社群文章中,幾乎被認為是不一樣的,這跟國外的文獻有所出入。我們決定寄信向uClinux貢獻者David McCullough詢問,得到以下答案:
Hi,
kmalloc2 = linux-2.0.x
page_alloc2 = linux-2.4.x
The only real difference is the kernel the code works on, underneath they
used mostly the same concepts,
Cheers,
Davidm
沒有brk/sbrk()
brk/sbrk()用途在於增加或減少一個行程可用的記憶體空間。uClinux在硬體啟動時每個行程分配在連續的記憶體上,由於缺乏虛擬記憶體機制,行程無法擴展其可用記憶體,因此無有效的brk/sbrk()實作方式。無法擴展時,只能從將整個行程移到另一塊足夠大小的連續記憶體上,由全域記憶體(Kernel free memory pool)直接分配。這樣做可以節省記憶體使用量,因為當行程需要記憶體的時候,系統才會分配。在行程用完後,會將記憶體還給全域記憶體(相對於使用pre-allocated heap system)。
vfork
在Linux中,fork()藉由copy-on-write來實作,而copy-on-write的實現需要MMU,因此uClinux難以實作fork(),改使用vfork()替代。 也就是說parent process 和 child process 是共享同一個記憶體。 parent process 在初始化私有(private)的資料和建立新的task control block 後,進入suspend 狀態。 而child process 則取代現在的程式,直到執行exec()或exit()後把parent process 喚醒。 - 描述 fork和vfork擁有相同的效果,但如果下列情況發生,vfork的行為無法被定義。 1.修改用來回傳型態為pid_t以外的資料 2.成功呼叫calling _exit(2)或是exec(3)系列的程式前,呼叫任何其他的程式 3.從有使用vfork的程式中傳回
檔案系統名詞解釋
Superblock
為每個檔案系統開始的位置, 其儲存資訊像是檔案系統的大小,空的和填滿的區塊,它們各自的總數和其他諸如此類的資料。
要從一個檔案系統中存取任何檔案皆須經過檔案系統中之superblock。
如果superblock損壞了, 可能無法從磁碟中去取得資料。
Inode
每個檔案或目錄由inode來表示,inode儲存的資訊包含有關大小、權限、所有權和硬碟上的檔案或目錄的位置資料。
uClinux的檔案系統:Romfs
由於沒辦法實作虛擬記憶體,所以必須採用romfs,因為它可以保證將檔案已連續的方式存放。
*特性
唯讀的檔案系統
無法寫入時複製(copy-on-write)
有多個呼叫者(callers)同時要求相同資源,他們會共同取得相同的指標指向相同的資源,直到某個呼叫者(caller)嘗試修改資源時。
系統才會真正複製一個副本(private copy)給該呼叫者,以避免被修改的資源被直接察覺到。
但因為uClinux沒有fork,故無法使用。
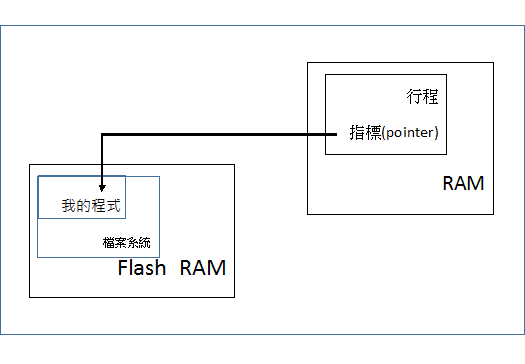
XIP(Execute in place)
程式直接在flash上執行,而不必搬到RAM上。可以減少memory的使用,但執行速度較慢。
未使用XIP的情況
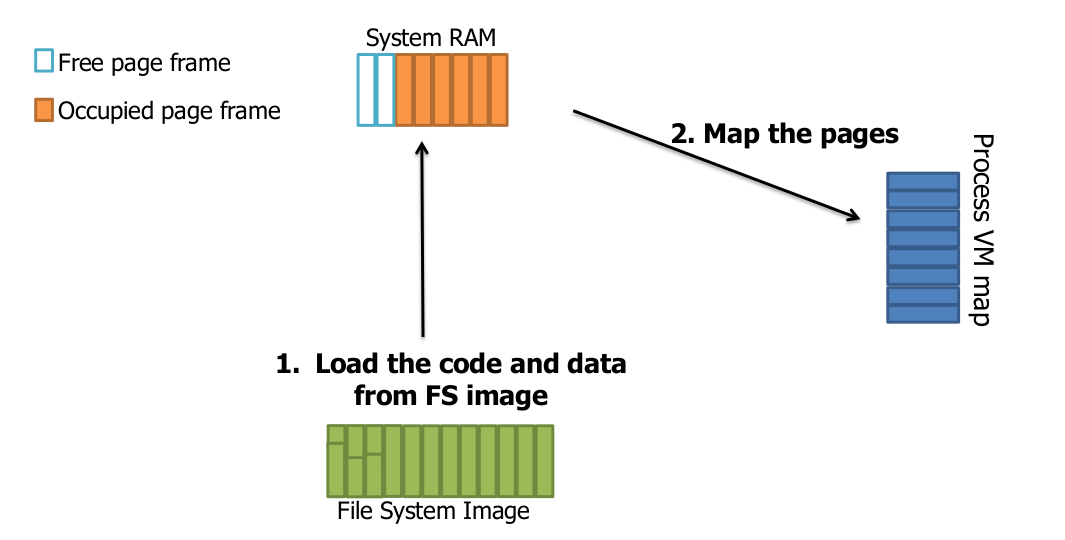
有VM的XIP

來源:http://elinux.org/images/8/8c/Elc2013_Kumar.pdf
下圖為uclinux下XIP示意圖(來源)
xip_file_read(定義在uclinux/mm/filemap_xip.c)
.. code-block:: c
ssize_t xip_file_read(struct file *filp, char __user *buf, size_t len, loff_t *ppos)
{
if (!access_ok(VERIFY_WRITE, buf, len)) // if the file can't access,return fault.
return -EFAULT;
return do_xip_mapping_read(filp->f_mapping, &filp->f_ra, filp, //mapping to the memory
buf, len, ppos);
}
do_xip_mapping_read
.. code-block:: c
do_xip_mapping_read(struct address_space *mapping,
struct file_ra_state *_ra,
struct file *filp,
char __user *buf,
size_t len,
loff_t *ppos)
{
struct inode *inode = mapping->host;
pgoff_t index, end_index;
unsigned long offset;
loff_t isize, pos;
size_t copied = 0, error = 0;
BUG_ON(!mapping->a_ops->get_xip_mem);//a_op 為 address_space 中定義可用的method
pos = *ppos;
index = pos >> PAGE_CACHE_SHIFT;//PAGE_CACHE_SHIFT 在不同的硬體上值會不同
offset = pos & ~PAGE_CACHE_MASK;
isize = i_size_read(inode);
if (!isize)
goto out;
end_index = (isize - 1) >> PAGE_CACHE_SHIFT;// ex.如果需要讀取的大小為4KB,則只需讀取一次。
//(PAGE_CACHE_SHIFT 為 12)
do {
unsigned long nr, left;
void *xip_mem;
unsigned long xip_pfn;
int zero = 0;
/* nr is the maximum number of bytes to copy from this page */
nr = PAGE_CACHE_SIZE;
if (index >= end_index) {
if (index > end_index)
goto out;
nr = ((isize - 1) & ~PAGE_CACHE_MASK) + 1;
if (nr <= offset) {
goto out;
}
}
nr = nr - offset;
if (nr > len - copied)
nr = len - copied;
error = mapping->a_ops->get_xip_mem(mapping, index, 0,
&xip_mem, &xip_pfn);
if (unlikely(error)) {
if (error == -ENODATA) {
/* sparse */
zero = 1;
} else
goto out;
}
if (mapping_writably_mapped(mapping))//if it is writable,return false.
/* address based flush */ ;
if (!zero)
left = __copy_to_user(buf+copied, xip_mem+offset, nr);
else
left = __clear_user(buf + copied, nr);
if (left) {
error = -EFAULT;
goto out;
}
//如果可以被寫入,left值為0,即整個page為vaild location
copied += (nr - left);
offset += (nr - left);
index += offset >> PAGE_CACHE_SHIFT;
offset &= ~PAGE_CACHE_MASK;
} while (copied < len); //如果還沒讀取完,則繼續
out:
*ppos = pos + copied;
if (filp)
file_accessed(filp);
return (copied ? copied : error);
}
i_size_read
.. code-block:: c
static inline loff_t i_size_read(const struct inode *inode)
{
#if BITS_PER_LONG==32 && defined(CONFIG_SMP)//如果在多核心架構下,即使排程器是允許搶奪機制,也不會影響到其讀取
loff_t i_size;
unsigned int seq;
do {
seq = read_seqcount_begin(&inode->i_size_seqcount);
i_size = inode->i_size;
} while (read_seqcount_retry(&inode->i_size_seqcount, seq));
return i_size;
#elif BITS_PER_LONG==32 && defined(CONFIG_PREEMPT)//如果在讀取時被搶奪,有可能造成deadlock
//如果有一個高權限(須為real time process)的行程去搶低權限的行程,但低權限的擁有某資源的lock,而高權限的也要存取此資源
//則會形成deadlock(存取low word & high word 中間時被搶奪時發生)
loff_t i_size;
preempt_disable();
i_size = inode->i_size;//因為i_size 為64 bit,如果再64bit CPU架構下,無須分2次存取。
preempt_enable();
return i_size;
#else
return inode->i_size;
#endif
}romfs結構(來源)

romfs_super_block 結構 定義在 include/linux/romfs_fs.h
.. code-block:: c
struct romfs_super_block {
__be32 word0;
__be32 word1;
__be32 size;
__be32 checksum;
char name[0];//volume name : 使用者給予此系統一個名稱
};word0和word1的值是固定的,其值分別為 “-rom” 和 “1fs-”,使系統知道它是romfs檔案系統。
size表示romfs系統合法存取的大小(整個檔案系統的大小),也就是最後一個檔案的結束位置。
checksum用來檢查檔案的正確性
romfs_checksum定義在 fs/romfs/super.c line:499
- romfs_inode結構
.. code-block:: c
struct romfs_inode {
__be32 next; /* low 4 bits see ROMFH_ */
__be32 spec;
__be32 size;
__be32 checksum;
char name[0];
};spec表示檔案類型定義在include/linux/romfs_fs.h
.. code-block:: c
#define ROMFH_HRD 0 //永久連結(hard link)
#define ROMFH_DIR 1 //目錄(directory)
#define ROMFH_REG 2 //一般(regular file)
#define ROMFH_LNK 3 //連結(symbolic link)
#define ROMFH_BLK 4 //block device
#define ROMFH_CHR 5 //character device
#define ROMFH_SCK 6 //socket
#define ROMFH_FIF 7 //fifo hard link 與 symbolic link
hard link是系統中有效的連結,所儲存的內容會指向記憶體中 而 symbolic link,則是把指標指向hard link,所以如果所指向的hard link被刪除,就無法再存取此檔案了。block device和character device
兩個都是跟IO有關。 block device為固定大小長度來傳送資料且可以隨機存取,如硬碟或是光碟機。 而character device 以不定長度的字元傳送資料且只能循序存取,如終端機、印表機。
EXT2
在uClinux保留了ext2,使mount可以在此系統下運作。
在 EXT2 檔案系統中,目錄是被用來創造並且在檔案系統中保持存取路徑到檔案的特殊檔案。
下圖是目錄的結構 (來源)

ext2_inode示意圖 (來源)
Process State
uclinux 的狀態與 linux 相似,其狀態定義在include/linux/sched.h : line 183
.. code-block:: c
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
#define __TASK_STOPPED 4
#define __TASK_TRACED 8
/* in tsk->exit_state */
#define EXIT_ZOMBIE 16
#define EXIT_DEAD 32
/* in tsk->state again */
#define TASK_DEAD 64
#define TASK_WAKEKILL 128
#define TASK_WAKING 256
#define TASK_STATE_MAX 512 //如果把各種的state 用or operation 去定義,其值最大為511下圖為狀態示意圖 (來源:<> 任哲 樊生文編著)
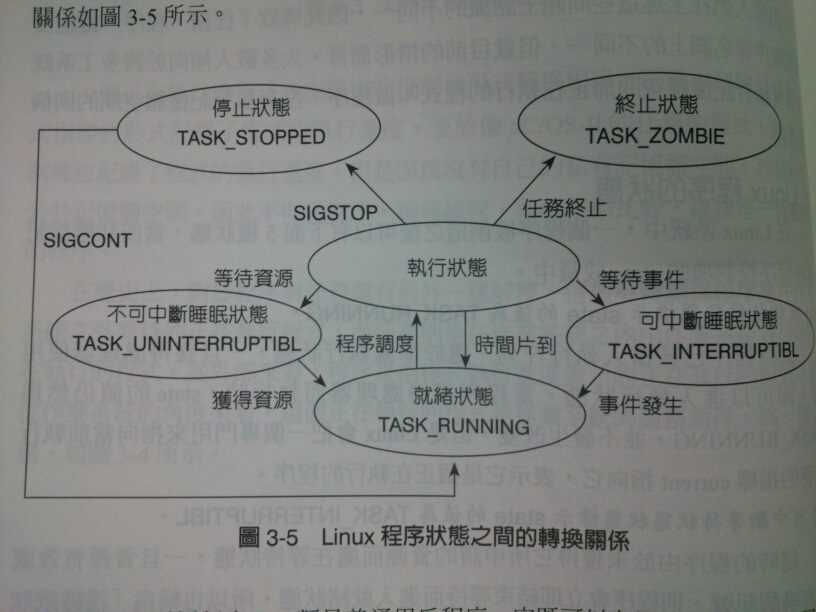
process state 切換的條件
給予某process時間 結束,必須將resource交給其他的process。
等待某個裝置或是process回應,而自己進入睡眠。
Scheduler
改變系統schedule方式
定義在kernel/sched.c:line6293
.. code-block:: c
static int __sched_setscheduler(struct task_struct *p, int policy, struct sched_param *param, bool user) { int retval, oldprio, oldpolicy = -1, on_rq, running; unsigned long flags; const struct sched_class *prev_class = p->sched_class; struct rq *rq; int reset_on_fork; /* may grab non-irq protected spin_locks */ BUG_ON(in_interrupt()); recheck: /* double check policy once rq lock held */ if (policy < 0) {//輸入為無效的排程方式,將變數設定成跟原排程方式相同 reset_on_fork = p->sched_reset_on_fork; policy = oldpolicy = p->policy; } else { reset_on_fork = !!(policy & SCHED_RESET_ON_FORK); policy &= ~SCHED_RESET_ON_FORK; if (policy != SCHED_FIFO && policy != SCHED_RR && //只有這五種為有效的排程方式 policy != SCHED_NORMAL && policy != SCHED_BATCH && policy != SCHED_IDLE) return -EINVAL; } /* * Valid priorities for SCHED_FIFO and SCHED_RR are * 1..MAX_USER_RT_PRIO-1, valid priority for SCHED_NORMAL, * SCHED_BATCH and SCHED_IDLE is 0. */ if (param->sched_priority < 0 || //檢查給予的權限值是否在有效的排程範圍內 (p->mm && param->sched_priority > MAX_USER_RT_PRIO-1) || (!p->mm && param->sched_priority > MAX_RT_PRIO-1)) return -EINVAL; if (rt_policy(policy) != (param->sched_priority != 0)) return -EINVAL; /* * Allow unprivileged RT tasks to decrease priority: */ if (user && !capable(CAP_SYS_NICE)) { if (rt_policy(policy)) { unsigned long rlim_rtprio; if (!lock_task_sighand(p, &flags)) return -ESRCH; rlim_rtprio = p->signal->rlim[RLIMIT_RTPRIO].rlim_cur; unlock_task_sighand(p, &flags); /* can't set/change the rt policy */ if (policy != p->policy && !rlim_rtprio) return -EPERM; /* can't increase priority */ if (param->sched_priority > p->rt_priority && param->sched_priority > rlim_rtprio) return -EPERM; } /* * Like positive nice levels, dont allow tasks to * move out of SCHED_IDLE either: */ if (p->policy == SCHED_IDLE && policy != SCHED_IDLE) return -EPERM; /* can't change other user's priorities */ if (!check_same_owner(p)) return -EPERM; /* Normal users shall not reset the sched_reset_on_fork flag */ if (p->sched_reset_on_fork && !reset_on_fork) return -EPERM; } if (user) { #ifdef CONFIG_RT_GROUP_SCHED /* * Do not allow realtime tasks into groups that have no runtime * assigned. */ if (rt_bandwidth_enabled() && rt_policy(policy) && task_group(p)->rt_bandwidth.rt_runtime == 0) return -EPERM; #endif retval = security_task_setscheduler(p, policy, param); if (retval) return retval; } /* * make sure no PI-waiters arrive (or leave) while we are * changing the priority of the task: */ raw_spin_lock_irqsave(&p->pi_lock, flags); /* * To be able to change p->policy safely, the apropriate * runqueue lock must be held. */ rq = __task_rq_lock(p); /* recheck policy now with rq lock held */ if (unlikely(oldpolicy != -1 && oldpolicy != p->policy)) { policy = oldpolicy = -1; __task_rq_unlock(rq); raw_spin_unlock_irqrestore(&p->pi_lock, flags); goto recheck; } update_rq_clock(rq); on_rq = p->se.on_rq; running = task_current(rq, p); if (on_rq) deactivate_task(rq, p, 0); if (running) p->sched_class->put_prev_task(rq, p); p->sched_reset_on_fork = reset_on_fork; oldprio = p->prio; __setscheduler(rq, p, policy, param->sched_priority); if (running) p->sched_class->set_curr_task(rq); if (on_rq) { activate_task(rq, p, 0); check_class_changed(rq, p, prev_class, oldprio, running); } __task_rq_unlock(rq); raw_spin_unlock_irqrestore(&p->pi_lock, flags); rt_mutex_adjust_pi(p); return 0; }
*關於BUG_ON(condition)和BUG()
定義在 include/asm-generic/bug.h 中
.. code-block:: c
#define BUG_ON(condition) do {if(unlikely(condition))BUG();}while(0);
用來判斷kernel 是否出現問題,如果傳入BUG_ON(condition)的參數為true ,則確認有bug出現。
系統會將BUG訊息印出,然後呼叫panic 。
- BUG()
.. code-block:: c
#define BUG() do{\
printk("BUG:failure at %s:%d/%s()!\n",__FILE__,__LINE__,__func__));\
panic("BUG!");\
}while(0)
- unlikely()
用來提升pipeline的效益,此函式代表接下來的程式不太可能被執行。
所以在compile 時,compiler會調整指令順序,以提升執行效率。其內容定義在GCC的內建函式: __builtin_expect() 中。
likely()也是相同功能。Interrupt Handler
執行user process時,會根據kernel內建的排程演算法,由OS定期強制切換執行程式。因此user process稱為「preemptive (可被搶占的)」,這個切換process的動作稱為「context switch」,由kernel/sched.c底下的schedule()實作。schedule()會被kernel中的許多地方所呼叫,主要包含下列三者: user context開始sleep的時候 嚐試鎖定spin lock的時候(enable CONFIG_PREEMPT) timer scheduler呼叫時
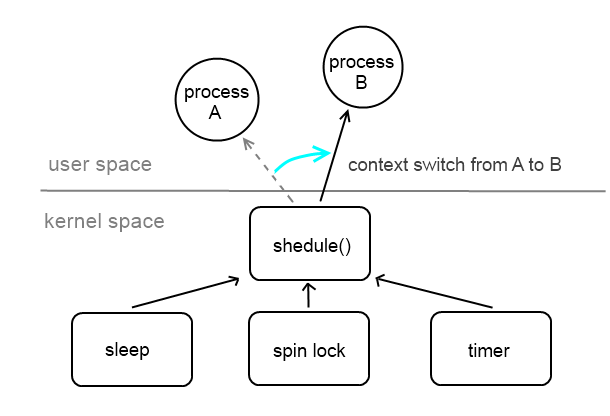
一個user space 的thread執行到一半時,可能會因為上述原因觸發process scheduler,始得CPU轉而執行另外一個thread。而linux kernel space的特徵之一即是他不是preemptive的,換句話說,一個處於kernel space中執行到的一半的thread並不會被process scheduler強行暫停。唯一的例外是發生hardware interrupt的時候,此時中斷處理函式會強制取得CPU的使用權(同時也意味著它有最高度的優先權)
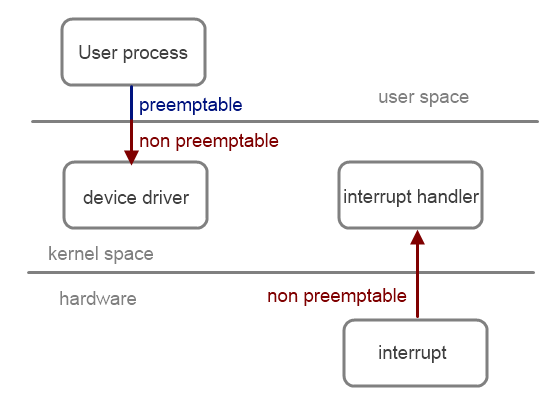
何謂 interrupt呢? 這是一個讓軟體(kernel)在接到來自硬體的通告,作出反應的機制。以網路卡為例,硬體在接收到外部的封包之後,便會以interrupt通知OS,展開對應此狀況的中斷處理程序(interrupt handler),運行架構如下圖所示。
而interrupt context具有最高優先權一事也意味著,scheduler動不了它,所以它不可陷入sleep,或是呼叫任何有機會導致本身sleep的system call,否則沒人叫的醒。基於同樣的理由,它也不可以被preempt。最後,interrupt context本身必須僅可能的簡短,若是花太多時間處理的話,將導致後續的interrupt被遺漏,引起其他問題。
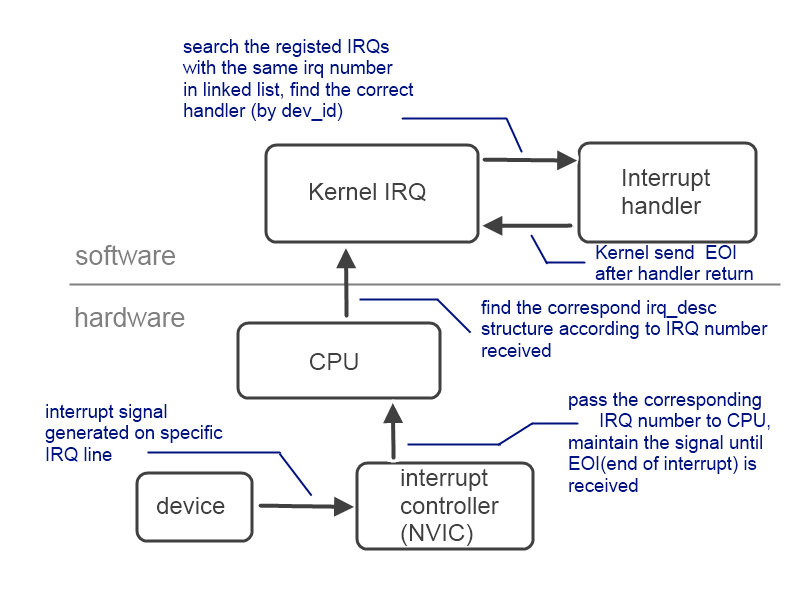
以STM32開發板為例,首先先來關心上圖中device至interrupt controller(NVIC)的部份,我們知道電子產品的信號多數都是電壓的改變,因此device對interrupt controller送出訊號的方式會是對後者送出某個特定的電壓訊號。考慮到可能有複數個device的狀況,便會有複數條線路用以傳送電壓訊號,此一線路稱為「IRQ line」,若要知道是哪個裝置發出訊號的話,只要檢察是哪條IRQ line送來的訊號即可。但隨著device數量增加,亦有多個device共用同一條IRQ line的情形。
若想收到控制的裝置送出的中斷訊號,就必須事先登記中段處理程序,這個過程多數是在驅動程式載入後,或是裝置初始化完成之後執行,使用的是request_irq()這個kernel/irq/manage.c底下的函式
.. code-block:: c
int request_irq( unsigned int irq, irqreturn_t handler, unsigned long irqflags, const char *devname, void *dev_id)- 變數概略說明如下 - irq即是IRQ line之編號 - handler為指向中斷處理函式之指標 - irqflags可以透過第n個位元的值來描述該irq的某些特徵,於<interrupt.h>中定義,像是IRQF_SHARED 標明了該irq是否共用同一條IRQ line等 - devname為/proc/interrupts記錄檔中會出現的裝置名稱 - dev_id用已辨明同一條IRQ line中不同的device用
每一個相同的IRQ line在linux中會串成一條link list,kernel在接獲一條IRQ line上產生的訊號時,會從link list的前端開始,沿路呼叫每一個node的handler function,而該handler function則必須檢查這個訊號是否由自身所屬的device所發出。若否,則handler function要盡快把控制權丟出來以免拖累整個interrupt handling的處理速度。若訊號源來自handler自己所對應的裝置,則在處理中斷工作結束後回傳IRQ_HANDLED。
list.png
接著我們以linux處理Level-Triggered Interrupts的流程來介紹maskng。所謂的Level-Triggered是指當我的輸入電位高過某個水平之後,即視為device遇到狀況了,需要CPU的關心。而在device本身降低自己在這個port的電壓前,電壓將持續的維持在高位。這意味著我們需要暫時無視這個port的訊號,待處理完interrupt handling後(順便期待處理會使的電位降低),重新檢視這個port的訊號。又或者是通知device controller說OS開始處理這個interrupt了,讓device決定下一步動作(例如降低該port之電位)。在下面這個流程圖中採取了雙管齊下的策略。
(補圖)
- 簡單的流程說明如下: - 當CPU收到一個irq request時,它會先遮蔽(mask)來自該irq line的訊號,並同時給 device controller 一個訊號(ack)表明已接收到這個interrupt。 - 接著檢查這個irq line是不是有其它的CPU已經先一步開始處理了,若有了就別管他。 - 再來檢查是否有handler function,或這個IRQ本身已被標記為就算發生了也別管他 - 通過上述檢查後,將IRQ_INPROGRESS對應的bit標記為1,防止半路殺出別的CPU接手 - 處理IRQ - 移除IRQ_INPROGRESS標記,以便unmask時又收到訊號可以被再次處理
觀察上面的簡要流程,會發現我們需要兩樣未提及東西:masking的控制,以及該條IRQ line的狀態。
其中將訊號遮蔽的masking可以透過寫入interrupt controller的register來達成。STM32使用的是cortex M處理器,其Nest Vector Interrupt Controller(NVIC) masking所對應的位址如下表。
![]()
而能在handler function層級中控制一個irq line的masking與否,意味著OS必須有能力處理不同硬體間的差異,如此一來才具備可攜性。這在linux底下主要透過三個資料結構,分別為irq_chip、 irqaction以及 irq_desc來達成,其主要成員如下。
\include\linux\irq.h
.. code-block:: c
struct irq_chip { const char *name; void (*enable)(unsigned int irq); void (*disable)(unsigned int irq); void (*ack)(unsigned int irq); void (*mask)(unsigned int irq); void (*mask_ack)(unsigned int irq); void (*unmask)(unsigned int irq); .... .... }\include\linux\interrupt.h
.. code-block:: c
struct irqaction { irq_handler_t handler; unsigned long flags; const char *name; void *dev_id; struct irqaction *next; ... ... };\include\linux\irq.h
.. code-block:: c
struct irq_desc { unsigned int irq; struct irq_chip *chip; struct irqaction *action; /* IRQ action list */ unsigned int status; /* IRQ status */ ... .... }
irq_desc,如同其名稱(discription)所示,內描述了該條IRQ line的狀態,所有操作皆可透過他達成。irq_desc中有兩個指標分別指向了irq_chip以及irqaction兩個結構,前者負責與最底層硬體的溝通,後者則是處理interrupt service routine重要的一員,三者的關係如下圖所示。inturrupt發生時OS會沿著該條IRQ line檢察是否有符合的device id,並呼叫對應的handler function。
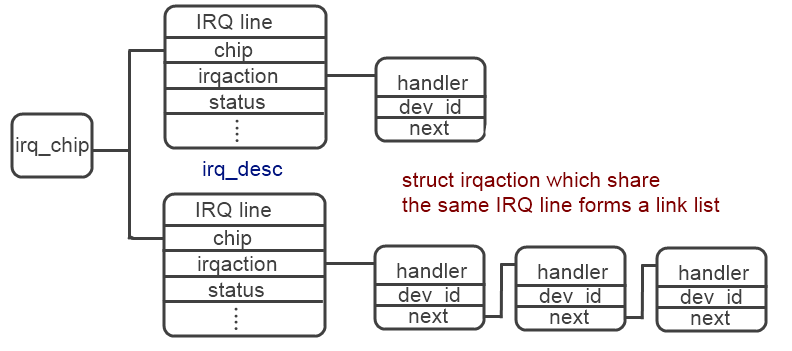
從最底層最接近硬體的部分開始,我們可以看見irq_chip這個struct底下主要由一系列指向函數指標所組成。以mask當作例子,可以在在nvic.c底下找到nvic_mask_irq這個函數直接操作硬體register的函數,其中 NVIC_CLEAR_ENABLE為對應上表register,為0xe000e000e180,將特定的bit設為1之後即可遮蓋特定的IRQ line
.. code-block:: c
static void nvic_mask_irq(unsigned int irq)
{
u32 mask = 1 << (irq % 32);
spin_lock(&irq_controller_lock);
writel(mask, NVIC_CLEAR_ENABLE + irq / 32 * 4);
spin_unlock(&irq_controller_lock);
}接著我們可以在同樣一份nvic.c底下找到屬於struct irq_chip的nvic_chip與nvic_mask_irq這個函數的關聯
.. code-block:: c
static struct irq_chip nvic_chip = {
.name = "NVIC",
.ack = nvic_ack_irq,
.mask = nvic_mask_irq,
.unmask = nvic_unmask_irq,
}以及在nvic初始化中的迴圈有一段 set_irq_chip(i, &nvic_chip)。這個函數的功能是將nvic_chip,包裝到資料結構struct irq_desc底下,以及初始化一些nvic_chip中未填入的資訊。上層函數若需要呼叫nvic_mask_irq()這個函數時,只要持有相對應的irq_desc,利用
.. code-block:: c
desc->chip->mask(irq)即可達成在handler層級使用相同的code控制不同硬體之目標。
名詞介紹IRQ (ARM Instruction Set 介紹)
ARM Instruction Set
processor mode
User模式: 非特權模式(大多數工作所跑得模式)
FIQ模式 :當比較高的優先權中斷提出時的模式
IRQ模式 :當比較高的優先權中斷提出時的模式
Supervisor模式:當要reset和軟體中斷時的模式
Abort 模式: 記憶體保護處理模式
Undef模式:用來處理未定義指令的模式
ARM Architecture Version 4 加了第七種模式
- System模式: 專門給作業系統工作的特權模式
The Registers
有一個 program counter
有一個 current program status register
有五個 saved program status registers
有三十個 general purpose registers
每個模式可以存取
r0-r12 暫存器
r13 (the stack pointer) and r14 (link register)
r15 (the program counter)
cpsr (the current program status register)
特權模式可以多存取
- spsr (saved program status register)
電流處理 (Flow Handler)
邊緣觸發中斷:

條件觸發中斷:

其他類型的中斷(較不常用):
handle_fasteoi_irq 如果中斷處理程序正在執行,則呼叫desc->chip->eoi 並返回。
handle_simple_irq 與handle_fasteoi_irq相似。差別在於若未定義action或 IRQ被禁用時,它會直接離開;而handle_fasteoi_irq會把IRQ狀態設成PENDING後mask掉該interrupt。
handle_percpu_irq 有些IRQ只發生在特定一個CPU上,沒有lock的需求。
Interrupt Overview
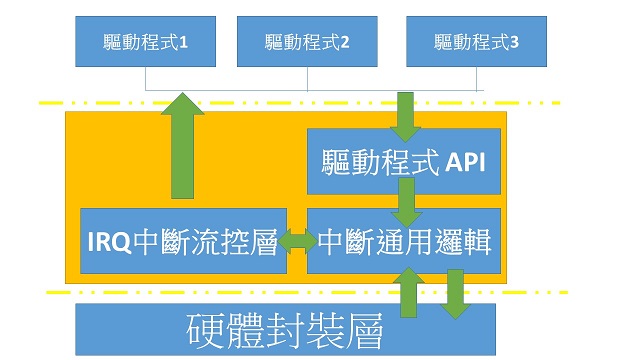
GPIO
爲了讓開發者能針對自己的使用需求來做開發,GPIO就顯得特別重要。
它能讓開發者進行硬體擴充。每個GPIO 的 input signal 和 output signal 會對應到特定的腳位。
在 STM32F429開發板上,每個GPIO有對應的編號(0~127):
.. code-block:: c
~# cd /sys/class/gpio
/sys/class/gpio # ls
export gpiochip0 unexport
/sys/class/gpio # cat gpiochip0/ngpio
128NVIC
NVIC是Cortex-M處理器的一部份。負責處理例外和中斷的設定,包括中斷的優先權和遮罩。他有一些很棒的特性
彈性的控制和設定
每個ISR都可以獨立做啟動與關閉
允許巢狀中斷,也就是中斷時,還可以被中斷
每個Exception都有自己的優先權,有些可以自由設定優先權,少數嚴重的例外不可以 (Reset, NMI, HardFault的優先權是固定的,不可改變)
當例外發生時,NVIC會比較例外的優先權,如果後來發生的exception優先權比較高,那就插隊先執行更優先的例外,也就是preemption。
可以做中斷遮罩,也就是停用某些中斷
Cotex-M3, M4提供了幾個遮罩register,例如PRIMASK,你可以停用所有的exception(除了最嚴重的HardFault和NMI不可以停用),
好處是當你在執行一些關鍵任務,不可以被打斷(例如看片執行real-time multimedia解碼時)。
或是你可以使用BASEPRI register,來停用某個優先權以下的例外。
硬體驅動原理
- GPIO
- EXTI, NVIC
- interrupt handling
效能表現
Q&A
Q1. Relationship between fork() and MMU.
如果整個程式中如果有指標的話,儲存指標類的資料會跟parent process的相同。
若父行程中有指標,例如
.. code-block:: c
int a=0;
int *b=&a;如果用只是單純的複製
從child process 去更動 *b的值,在child process中的a 值不會改變,而是parent process的值會被改變。
所以在fork時需要MMU,來確保這些指標指向的地址是正確的。
Q2. What is TLB?
Translation Lookaside Buffer,為一種cache,可加快mapping的速度。
如果TLB hit,CPU直接去對應的記憶體位置抓取指令;如果TLB miss,則去page_table中找對應的記憶體位置抓取指令;
如果產生page fault,則只能去storage把程式載入到記憶體中。

Q3. What is slab & slob allocator?
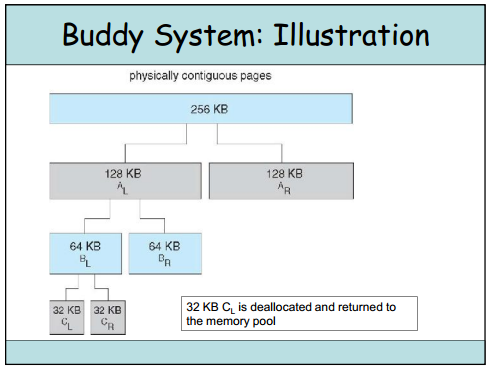
Q4. What is buddy?
一種記憶體分配的方式,將一個連續記憶體對半切,直到行程所需的記憶體大小介於(現在切割的大小)與(現在切割的大小/2)之間。
其好處在於演算法容易實作,且只需要以binary tree的方式來維護即可。
下圖為示意圖(來源)
Q5. How program loader load OS?(以uClinux為例)
1.載入OS的資料區段
2.OS kernel初始化,kernel以XIP的方式執行而資料區段儲存在RAM
3.載入應用程式
Q6. Real example about task states change.
Q7. What is IOMMU?
I/O Memory Management Unit([IOMMU](http://www.mulix.org/lectures/using-iommus-for-virtualization/OLS-jdmason.pdf))最初由AMD提出,是管理設備對記憶體的存取。它位于設備和主機之間,將來自設備請求的位址轉換成記憶體位址,並檢查訪問權限。
好處:存取的記憶體空間可以不連續。Q8. Why does volume name declared as name[0]?
.. code-block:: c
struct romfs_super_block {
...
char name[0];//volume name : 使用者給予此系統一個名稱
};
1.減少記憶體的浪費,如果給一個固定的大小,在volume小的情況下,會造成浪費,且限制名字的長度。
2.可以直接以romfs_super_block ->name存取。
3.用sizeof(struct romfs_super_block)會發現char name[0]不占空間。